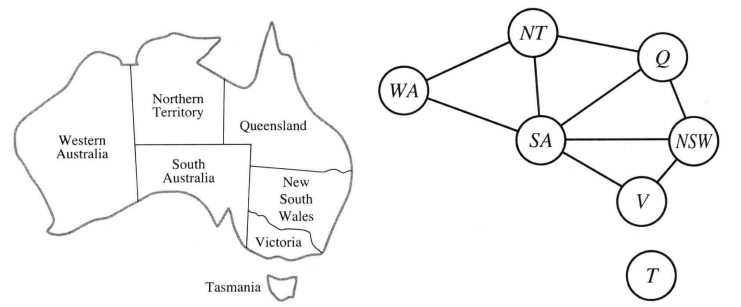
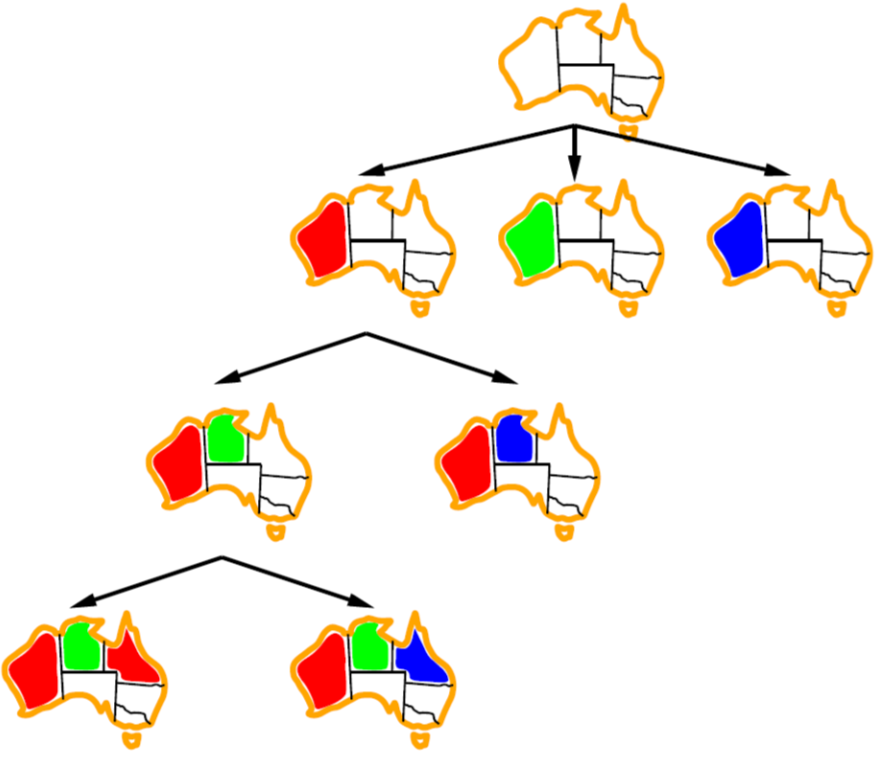
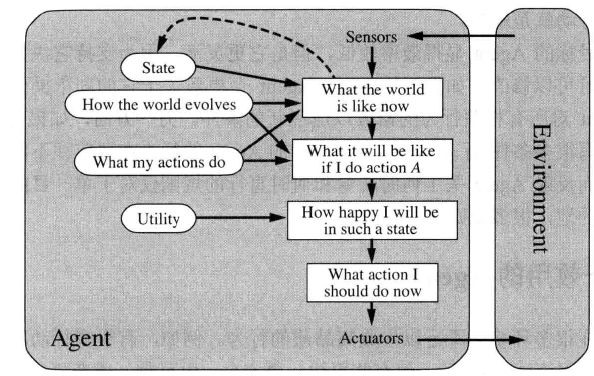
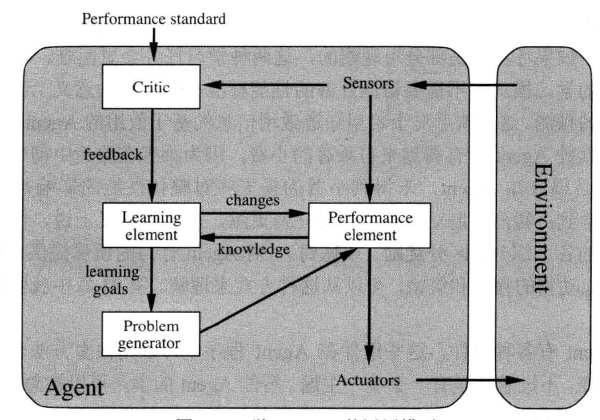
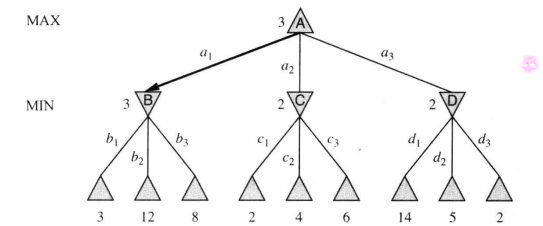
def max-value(state): initialize v = -∞ for each successor of state: v = max(v, value(successor)) return v def min-value(state): initialize v = +∞ for each successor of state: v = min(v, value(successor)) return v def value(state): if the state is a terminal state: return the state’s utility if the next agent is MAX: return max-value(state) if the next agent is MIN: return min-value(state)
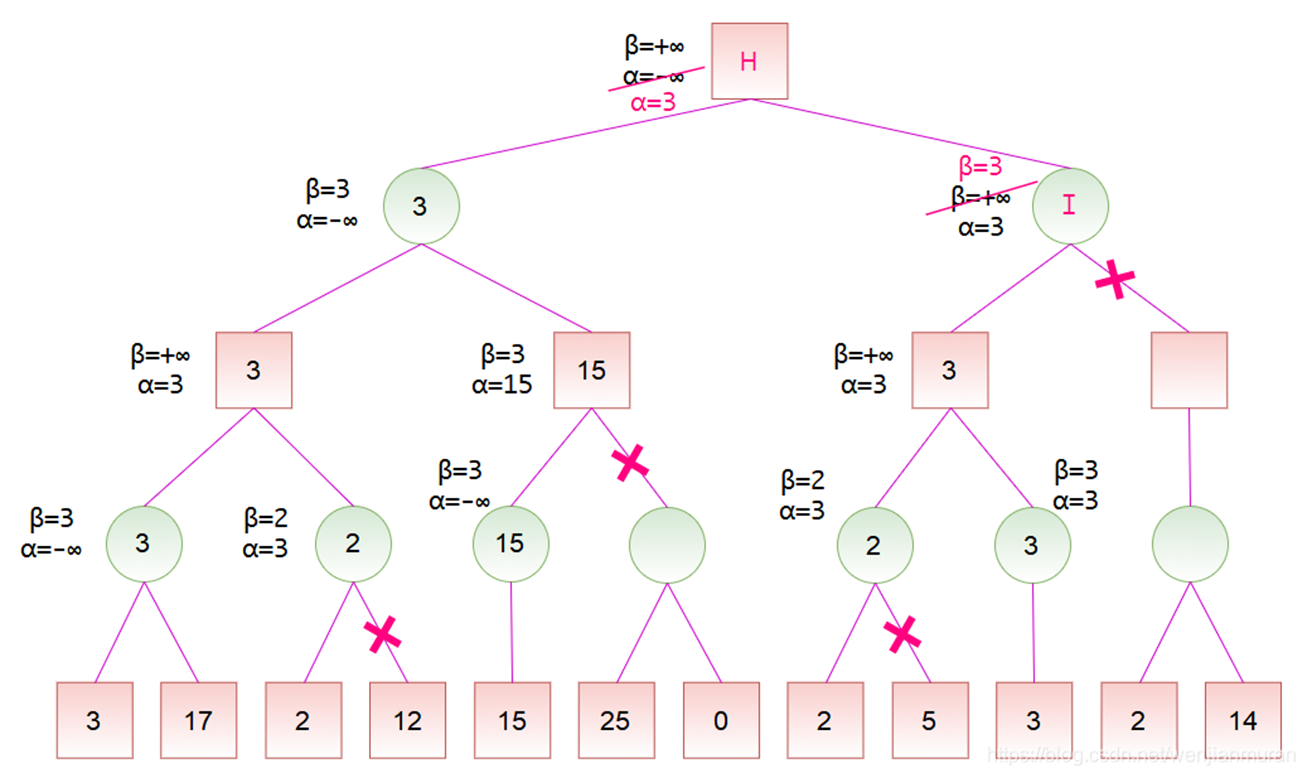
def max-value(state, α, β): initialize v = -∞ for each successor of state: v = max(v, value(successor, α, β)) if v ≥ β return v α = max(α, v) return v def min-value(state , α, β): initialize v = +∞ for each successor of state: v = min(v, value(successor, α, β)) if v ≤ α return v β = min(β, v) return v def value(state): if the state is a terminal state: return the state’s utility if the next agent is MAX: return max-value(state, -∞, +∞) if the next agent is MIN: return min-value(state, -∞, +∞)