EGOEXO-GEN: EGO-CENTRIC VIDEO PREDICTION BY WATCHING EXO-CENTRIC VIDEOS
Abstract
以第一人称视角生成视频在 Augmented Reality(AR)和 Embodied Intelligence 领域具有广阔的应用前景。在这项工作中,我们探索了跨视图视频预测任务,其中给定 exo-centric 视频、相应 ego-centric 视频的第一帧和textual instructions,目标是生成 ego-centric 视频的未来帧。受 ego-centric 视频中的hand-object interactions(HOI) 代表当前演员的主要意图和动作这一概念的启发,我们提出了 EgoExo-Gen,它对 cross-view 视频预测的 hand-object dynamics进行了显式建模。EgoExoGen由两个阶段组成。首先,我们设计了一个 cross-view HOI mask预测模型,该模型通过对 spatiotemporal ego-exo correspondence 进行建模来预测未来 ego-frames 中的 HOI masks。接下来,我们采用 video diffusion model 来使用第一个ego-frame和 textual instructions 来预测未来的ego-frames,同时将 HOI masks 作为结构指导以提高预测质量。为了促进训练,我们开发了一个自动化 pipeline,通过利用 vision foundation models 为 ego- and exo-videos 生成 pseudo HOI masks。大量实验表明,与之前在EgoExo 4D 和 H2O benchmark datasets 上的视频预测模型相比,我们提出的EgoExo-Gen 实现了更好的预测性能,HOI masks 显著改善了ego-centric 视频中手和交互对象的生成。
Introduction
本文考虑了基于在同一环境中同时捕获的第三人称(exo-centric)视频来animating 一个 ego-centric frame 任务。如下图所示,给定 ego-centric 视频的第一帧、一个 textual instruction 和同步的 exo-centric 视频,目标是 ego-view 后续帧。

Exo-centric 的视角通常提供更广泛的环境背景和身体运动,但不太关注fine-grained 的行动。相比之下, ego-centric 的视角集中在相机佩戴者的手和交互对象上,这对于 manipulation 和 navigation 等任务至关重要。cross-view 视频预测中的挑战来自于这些 views 之间的显著的 perspective shift ,因为未来帧必须与第一帧的上下文环境和由 textual instruction 和 exo-centric视频显示的 actor’s motion 两者对齐。
将这两种观点结合起来提供了两个关键好处:
- 它允许 agents 从第三人称演示中构建一个鲁棒的 ego-centric 世界模型,使他们能够将更广泛的场景信息转化为第一人称视角;
- 它使 agents 能够通过将其 viewpoint 与人类用户对齐,think from the humans’ perspective,提高他们预测未来行动并做出更明智决策的能力。
这种能力在增强现实(AR)和机器人技术等实时应用中特别有价值,其中 agents 必须使其 actions 与人类或环境同步。通过学习将 exo-centric 视频转换为准确的 ego-centric 帧, agents 在参与动态的现实世界环境时可以变得更加适应。
视频预测模型的最近研究已经显示出巨大的进步。这些模型主要依赖于第一帧和 textual instructions 作为 diffusion 的输入,主要重点是 exo-centric 的视角生成视频。关于 ego-centric的视频预测,探索了文本指令的分解,但缺乏针对 ego-centric 视角的定制设计。在 cross-view video generation 的背景下,已经开发了专门的模型。例如,(Luo et al., 2024a;b)利用来自 ego-centric 视频的头部轨迹数据来生成 exo-centric 视频中的 optical flow 和 occlusion maps,而(Luo et al., 2024b)估计了 ego-centric的视图中的手部姿势,以指导 conditional ego-video generation。然而,这些方法依赖于 3D场景重建或精确的 human annotations,限制了它们在不同场景中的可扩展性和泛化能力。
在本文中,我们提出了 EgoExo-Gen,这是一种 cross-view video prediction model ,通过显式建模 hand-object dynamics 来生成 ego-centric视频未来帧。EgoExo-Gen采用两阶段方法:
- 它在 ego-centric 的视角中预测hand-object interaction (HOI) masks;
- 其次,它使用这些 masks 作为条件,驱动 diffusion model 来产生相应的 RGB 帧。
对于 cross-view HOI mask prediction model,它将 exo-centric 视频和 ego-centric video 视频的第一帧作为输入,并预测 HOI 从而形成 masks ego-centric 未来帧。为了处理 viewpoints 的巨大变化,我们设计了一个ego-exo memory attention module,该模块捕捉两个视角之间的 spatio-temporal correspondences ,使模型能够推断 HOI masks,即使当前ego-centric 帧是不可见的。然后将预测的 HOI masks 集成到 diffusion model 中,指导准确的ego-centric 未来帧的生成。为了确保可扩展的训练并最大限度地减少对 manual annotations 的依赖,我们还通过利用强大的视觉基础模型,为 ego-centric 和 exo-centric 视频开发全自动的 HOI mask annotation pipeline。这种方法的组合使 EgoExo-Gen 能够生成高质量的 ego-centric 视频,同时显着提高不同环境中的可扩展性和通用性。
我们对 cross-view video benchmark datasets 进行了广泛的实验,即 EgoExo 4D(Grauman等人,2024年)和H2O(Kwon等人,2021),包括丰富多样的 handobject interactions 和拍摄环境。实验结果表明 EgoExo-Gen 显着优于先前的视频预测模型并通过利用 hand and object dynamics 来提高预测视频的质量。此外,EgoExo-Gen在不可见的动作和环境中表现出强大的零镜头传输能力。
Methodology
Problem Formulation
本文考虑了一个具有挑战性的问题,即基于在同一时间和同一环境中捕获的 exocentric 视频,animating 一个ego-centric帧。具体来说,给定具有 帧的 exo-centric 视频,、ego-centric 第一帧和text instruction ,我们的目标是预测接下来的 ego-centric 视频。值得注意的是,以ego-centric 和 exo-centric视频的摄像机姿势和深度信息均不可用,以鼓励开发可以在不同摄像机和地点推广的方法。请注意,与 cross-view correspondence benchmark 和exo-to-ego image translation不同的是,我们考虑的问题仅假设在测试时以自我为中心的观点有一个开始帧可用,这使得这项任务显着更具挑战性。
Overview
我们提出了EgoExo-Gen,通过显式建模 hand-object dynamics ,能够根据其相应的exo-centric 视频来animating一个 ego-centric 视频帧。如下图所示,我们提出的模型包括:
- cross-view mask预测网络 ,其估计ego-video 的spatio-temporal hand-object segmentation masks;
- HOI已知下的 video diffusion model ,给定 hand-object masks, 用于估计RGB ego-frames ;
- 生成 ego-exo HOI segmentation masks 的全自动pipeline,用于训练所有的模型;
在推理时,整个过程可以公式化为:

cross-view mask prediction
本节详细介绍了 cross-view mask 预测模型 ,该模型将 hand-object masks 从 exo-centric 转换为 ego-centric 视角。具体而言,该模型将以下内容作为输入:
- exo-centric 视频;
- exo-centric 视频的逐帧 hand object masks , 包括背景、手部和对象;
- ego-centric 视频的第一帧 。
期望的输出是以自回归方式生成的 ego-centric 视角中的对应的逐帧hand-object masks 。
在下面的部分中,我们只在训练时呈现整个 pipeline,而在推理过程中,我们只假设 ego-centric 视角中有一个起始帧可用,从而将 ego-centric 视频替换为ego-centric 视频的第一帧,以及后续以自我为中心的帧的所有 zero images。
Image and mask feature encoding
对于image encoder,我们采用共享的 ResNet,删除了最后一个卷积块。编image encoder 将 exo- and ego-frame 作为输入,并分别输出 exo- and ego-features:
mask encoder 将当前 exo-frame 和 exo-mask 的拼接作为输入,并使用另一个 ResNet 对它们进行编码。然后它通过 CBAM 块与 exo-image feature融合,并产生 exo-mask feature。
Ego-exo memory attention
该模块的核心是一个 memory bank ,它能够根据相应的 exo-centric 帧预测ego-centric 视频的 HOI mask features。
该模型以自回归方式操作,例如,当为第 个 ego-frame 生成时,
- 来自 exo-centric 视频的相应帧特征被视为
query, 历史 exo- and ego-frame features 被视为keys;例如; - 相应的 mask features 作为
values,例如为早期的mask features
其中 为线性变换,[]操作表示顺着时间维度进行拼接操作;第 个 ego-frame 的 mask feature 可以通过 cross-attention 获得
softmax操作在时间维度上执行, 在训练时,由于 ego-centric 视频中的所有帧都是可见的,因此我们还通过利用 ego-visual features作为query来获得剩余记忆输出,即 。记忆注意力模块的最终输出是,其中 在训练阶段从 退火至 。我们观察到这种策略有助于早期阶段的模型训练,并最终学会在推理时预测ego-centric所有帧的 mask features。
Mask decoder
mask decoder 由 upsampling 块堆叠组成,每个 upsampling 块由两个convolution layers 组成,接着进行 bilinear upsampling operation。它接受来自 ego-exo memory attention 模块的 的输出,并将其与每个块的多尺度 ego-features 融合,类似于UNet。解码过程可以简化为:
其中 指的是来自缩小尺度 的 image encoder 的多尺度特征。
Memory store and update
如上所述,我们的 ego-exo memory bank分别存储过去空间图像和 mask features 的 keys和values信息。在时间处,我们将预测的 ego-mask 编码为 ego-mask feature
并将其与图像和 mask features 一起存储到 ego/exo memory bank中,即。在测试时,我们整合内存并丢弃过时的 features,同时始终保留接下来第一帧的可靠的 features,但我们并不强调这个过程是我们方法的贡献。
HOI-aware video diffusion model
HOI-aware video diffusion model 的目标是生成后续的 ego-video 帧 ,给定第一帧 、text instruction 和已预测的 ego-centric handobject masks 。
Base architecture
Following (Rombach et al., 2022b),diffusion 和 denoising 过程是在 latent space中进行的。由以下部分组成
- 预训练的 VAE 编码器 和 解码器 ,用于对 ego-centric 视频进行逐帧编码/解码;
- 用于对 handobject masks 进行编码的mask encoder ;
- denoising UNet ,参数为;
Following (Chen et al., 2023; Ren et al., 2024),UNet 架构是基于预先训练的text-to-image 模型构建的。在每个 down/upsampling 块中,堆叠了 ResNet块、spatial self-attention 层和 cross-attention 层。附加了额外的 temporal attention层来建模cross-frame relationship。
U-Net 是一种卷积神经网络架构,名字来源于其独特的 U 形结构,是语义分割 任务的基准模型之一。
Encode / downsampling 块:捕获图像的上下文信息,每个模块包含:两个 3×3 卷积 + ReLU 激活函数,一个 2×2 最大池化;在特征图变化上,通道数加倍,空间尺寸减半
- 输入:572×572×1
- 经过编码器:64→128→256→512→1024
Decode/ upsampling 块:实现精确定位,每个模块包含:一个 2×2 转置卷积(上采样)与对应 downsampling 块 的特征图进行跳跃连接,两个 3×3 卷积 + ReLU;特征图变化上:通道数减半,空间尺寸加倍;
跳跃连接将编码器中的高分辨率、低层特征与解码器中的上采样特征相结合;用于解决梯度消失问题,保留空间细节信息,以及结合来自解码器的语义信息和来自编码器的位置信息;
First frame and text guidance
ego-video 的第一帧 被注入到 diffusion model 中以实现视觉上下文引导。形式上,该模型将以下三项的拼接作为输入:
- 损坏的有噪视频帧;
- 未损坏的视频的 VAE feature representation,其中第 至第 帧的 features 设置为零;
- temporal mask 表示第一帧的可见性。
text instruction 通过 CLIP text encoder 进行 tokenised 和编码,然后通过cross-attention 注入到 UNet。
HOI mask guidance
为了将从 cross-view mask prediction model 获得的 hand-object masks 合并到video diffusion model 中,,我们通过单独的轻量级 mask encoder 并将 features 插入到 denoising UNet中。包含多个downsampling 块,每个 downsampling 块由 ResNet 块和 temporal attention 层组成。它将 HOI masks 作为输入并输出多尺度 spatio-temporal feature maps:
其中 mask feature ; 在每个 decoder 块中,通过逐元素相加将 mask features 与 latent features 融合,然后在线性投影后将其反馈到 temporal attention 层。HOI-aware video diffusion model的 训练目标表示为:
其中 是指 dissusion 的时间戳,以及 指代高斯噪声;
Data, Training and Inference Pipline
本节首先描述了自动生成 ego-centric和exo-centric 的 handobject masks的过程,该过程使我们能够超越对现有标记数据集的依赖,并扩展到更广泛的配对的ego and exo datasets。然后,我们为训练和推理过程列出outline。
Ego-Exo HOI mask construction
我们的注释管道如下图所示。
Ego-Exo mask annotation pipeline。我们首先使用hand-object detector/segmentor执行逐帧注释,并提示 Sam-2 跟踪视频中的 HOI masks。
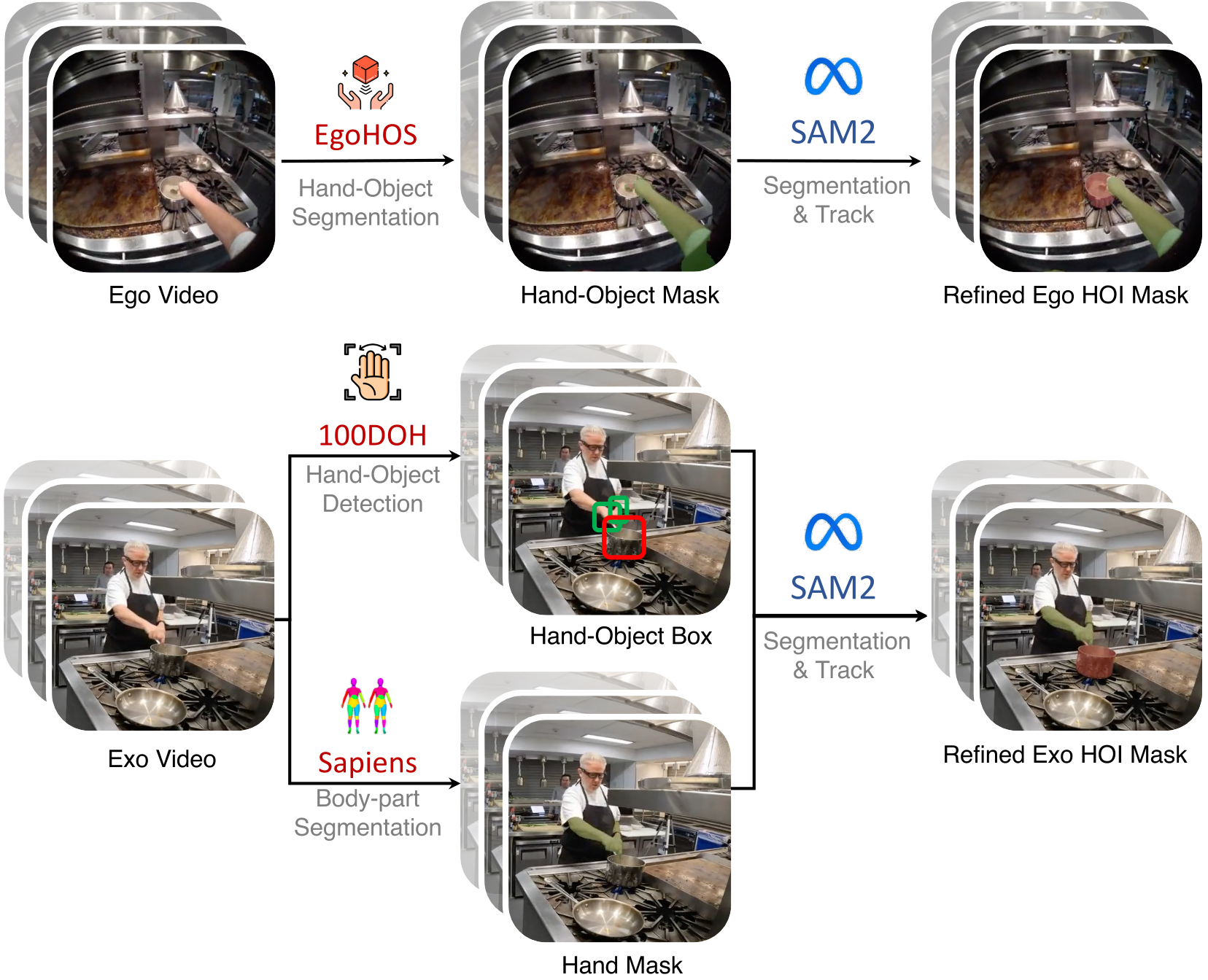 对于 ego-centric 视频,我们首先使用 EgoHOS 用于手和交互对象的每帧分割。尽管单个帧的结果良好,但 EgoHOS 未能捕捉帧之间的 temporal dynamics 。为了解决这个问题,我们利用 EgoHOS 生成的初始 hand-object masks 作为Sam-2的 prompts,实现 object tracking across frames ,并确保整个视频的 mask 一致性。对于 exo-centric 视频,EgoHOS 被证明不足以进行分割。相反,我们使用100 DOH 用于 hands and interactive objects 的逐帧检测。此外,我们采用了人类基金会模型 Sapiens 细分关键地区,即左手和右手、前臂和上臂。对于 ego-centric 视频, bounding boxes 和 masks 充当Sam-2的 prompts,以确保一致的 cross-frame tracking。
对于 ego-centric 视频,我们首先使用 EgoHOS 用于手和交互对象的每帧分割。尽管单个帧的结果良好,但 EgoHOS 未能捕捉帧之间的 temporal dynamics 。为了解决这个问题,我们利用 EgoHOS 生成的初始 hand-object masks 作为Sam-2的 prompts,实现 object tracking across frames ,并确保整个视频的 mask 一致性。对于 exo-centric 视频,EgoHOS 被证明不足以进行分割。相反,我们使用100 DOH 用于 hands and interactive objects 的逐帧检测。此外,我们采用了人类基金会模型 Sapiens 细分关键地区,即左手和右手、前臂和上臂。对于 ego-centric 视频, bounding boxes 和 masks 充当Sam-2的 prompts,以确保一致的 cross-frame tracking。
Training stage
为了训练 cross-view mask prediction model,我们使用二元交叉熵损失和Dice Loss 的和。
Dice Loss 是一种用于衡量两个样本集合相似度的统计指标;
其中为预测的分割区域,为真实的分割区域;
在实际的神经网络训练中,我们需要处理概率输出而不是二值分割,定义 为第 个像素的预测概率(经过 sigmoid), 为第 个像素的真实标签(0 或 1),用于防止除零错误的平滑项;
交叉熵损失会平等对待每个像素,但是如果 95% 是背景,5% 是目标,模型可能倾向于将所有像素预测为背景,依然获得 95% 的准确率
Dice Loss关注区域重叠度,即使背景占多数,如果目标区域预测错误,Dice Loss 会显著增大
随着训练的进行,我们逐渐 mask ego-frames,以鼓励模型在未观察到ego-frames时学习 cross-view correspondence。diffusion model 的训练过程分为两个阶段。
- 在第一阶段,我们使用 ego-centric 视频来训练 UNet backbone,使用第一帧和 textual instructions 作为条件,而不结合手-对象交互(HOI)。
- 在第二阶段,我们冻结 UNet backbone 并训练 mask encoder 和线性投影层。该阶段利用我们的自动数据 pipeline 生成的 ego hand-object masks,确保高质量的 mask 预测。
Inference stage
cross-view mask prediction model 将 exo-centric 视频、 exo-centric HOI masks和 ego-centric 视频的第一帧作为输入,并预测所有后续帧的ego-centric HOI masks。这些预测的 ego-centric HOI masks,以及ego-centric视频的第一帧,然后被输入到 diffusion model 中,以生成 ego-centric 未来帧。
Experiments
Dataset
在我们的实验中,我们选择Ego-Exo 4D数据集。Ego-Exo 4D是全球最大的多视图数据集,记录了1,286小时的视频。每个 ego-centric 视频至少有四个在同一环境中同时拍摄的 exo-centric 视频。我们选择属于烹饪场景的视频(在60个不同地点拍摄564小时),因为这些视频包含丰富的手与物体互动。训练集包含33,448个视频片段,平均持续时间为1秒。每个视频剪辑都与旁白配对(例如,C用右手将刀落在砧板上。)开始和结束时间戳。值得注意的是,Ego-Exo4D cross-view relation benchmark 包含特定对象的成对的ego-exo masks,然而,这些对象不保证是交互对象,并且 hand masks没有注释。相比之下,我们的自动注释过程包括手和交互式对象,提供更大的可扩展性。我们从验证集中抽取了1,000个视频片段,从中选择了500个视频片段,并使用 HOI masks 对其进行注释,以评估mask prediction model 的性能。训练和验证集有不同的takes,对模型对未见过的对象和位置的概括能力构成了挑战。为了评估该模型的零镜头传输能力,我们还采用了H2O(Kwon等人,2021年),一个专注于桌面活动的自我exo HOI数据集(例如,挤乳液,抓起喷雾剂)。H2O的验证集由122个带有动作标签的剪辑组成。
Implementation details
我们使用 Adam优化器训练 cross-view mask prediction model,epochs=30 batchsize=32。初始学习率设置为。我们为ego-centric和exo-centric的视频采样了个固定空间分辨率为480x480的帧。我们选择一个(四分之一)具有最高比例的exo-hand masks的exo-centric视频作为最佳视角,有效地最大限度地减少了遮挡问题。对于 video diffusion model,我们对两个阶段进行训练,epochs=10 batchsize=32,固定学习率为。我们使用 SEINE 初始化我们的模型, 在web-scale video-text pairs上进行预训练,并使用分辨率为256 x 256的个采样帧来训练模型。在推理过程中,我们采用 DDIM 采样器, 我们的实验中steps=100。
Evaluation metrics
Following(Grauman等人,2024),我们通过三个指标评估 cross-view mask prediction model:
- Intersection over Union(IoU):IoU评估地面实况掩码和预测之间的重叠;
- Contour Accuracy(CA): CA在应用平移以对齐它们的质心之后测量masks 的形状相似性;
- Location Error(LE):LE表示预测和地面实况掩码的质心之间的归一化距离。
关于视频预测模型的评估,我们采用SSIM、PSNR、LPIPS 和 FVD。
Quanlitative Comparision
Performance on Ego-Exo4D
我们将我们的方法与先前的视频预测模型进行比较,其中这些模型
- 第一帧作为条件:包括 SVD;
- 文本和第一帧作为条件:包括Seer,DynamiCrafter、SparseAlt,SEINE和ConstI 2 V。
我们在 EgoExo 4D 上对所有这些模型进行了微调,但SVD除外,我们发现其zero-shot性能更好。
如下表所示,微调的ConstitI 2 V和SEINE模型比视频预测模型实现了更高的准确性,尤其是分别在SSIM和LPIPS上。
Ego-Exo4D和零镜头转移到H2O的视频预测模型比较
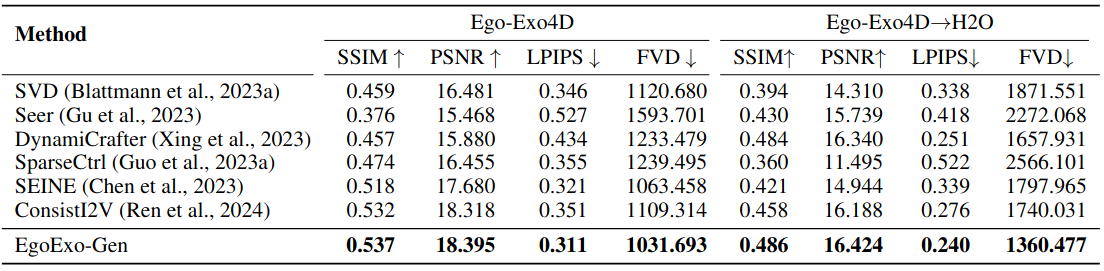
EgoExo-Gen在所有指标上始终优于先前的方法,凸显了在视频预测模型中显式建模 hand-object dynamics 的好处。
Zero-shot transfer to H2O
我们评估模型对未见数据分布的概括能力,即 H2O,包含执行桌面活动的手与物体互动的同步以自我为中心和外在为中心的视频。与Ego-Exo 4D相比,拍摄地点、上下文环境、对象和动作类别的区别给模型移植带来了挑战。如上表右侧所示,大多数方法都能实现相对较高的FVD;我们的方法通过有效地建模手和交互对象的运动,超越了这些模型,即使在无需重新训练的情况下直接从Ego-Exo 4D转移到H2O时也是如此。
Ablation Studies and Discussions
Analysis on the HOI condition
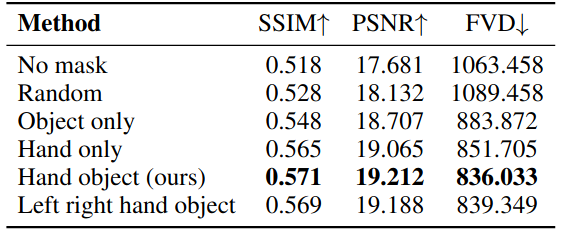
我们在下表中比较了不同的 hand-object conditions。为了保证 mask 的质量,这里我们应用从未来视频帧提取的 hand-object masks,而不是cross-view mask 预测。
- 如第一行所示,没有mask conditions 的视频预测模型 baseline 仅达到0.518 SSIM和17.681 PSNR。
- Random mask 不会比 baseline 有所改善,SSIM/PSNR更高,但LPIPS/FVD更低。
- 应用hand-only 或object-only masks 会比 baseline 模型产生显著的改进。
- 我们默认选择的hand-object masks 在所有指标上都达到了最佳效果,
- 区分左手和右手并不能进一步提高性能。
这些结果表明,双手和交互对象的细粒度控制对于ego-centric 视频预测至关重要。
不同手物条件下的比较。
Analysis on conditioning modalities
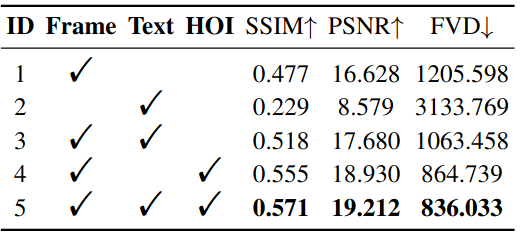
下表列出了应用不同模式作为视频预测任务的条件的比较结果。我们再次应用从未来视频中提取的 HOI masks 以保证 mask 的质量。
- 默认情况下,模型将第一个帧和 text instruction 作为输入作为条件,并预测后续帧(ID-3)。
- 放弃文本输入(ID-1)使预测的视频不再符合人类指令,导致可控性下降。
- 类似地,删除第一帧作为控制条件(ID-2)会将模型变成 Text-to-Video(T2V)模型。在这种情况下,模型无法在当前场景上下文中生成动作,因此性能显着下降(ID-1与ID-3)。
- 当结合第一帧和 HOI masks 时,该模型实现了优于基线的性能(ID-3与ID-4)。
这表明 structural control of the generation似乎比text instructions更有效,因为 hand-object movement可以作为推断当前动作语义的有价值的线索。相反,给定 textual instruction ,手和物体可能有多种实际互动和移动的方式。ID-5表明,将所有模式作为条件结合起来会产生最佳的预测性能。
作为视频预测条件的不同模式的比较。
Analysis on the cross-view mask prediction
我们研究了下表中的ego memory attention(作为query的 ego feature)和exo memory attention(作为query的exo feature)对cross-view mask prediction and video prediction 的影响。
- 第一行显示先验的性能,其中未来帧对cross-view mask prediction model可见。可以观察到分割和生成任务的高准确性,正如预期的那样。
- 如第二行所列,使用 ego-memory attention 只能产生较低的分割结果。尽管它对可见的第一帧进行了良好的分割,但它在后续帧中却遇到了困难,因为由于不可见性,它只能使用 zero-image features作为查询,因此很难有效地聚合历史信息。
- 相比之下,当仅使用exo-memory attention时,该模型可以对未观察到的帧做出比ego-memory attention更好的mask prediction,从而总体上更好的性能。
结合ego- and exo-memory attention协助早期阶段的模型训练,增强了在观察到和未观察到的帧中分割手和物体的预测能力,并随后改进了视频预测模型。
Analysis on exocentric video clues
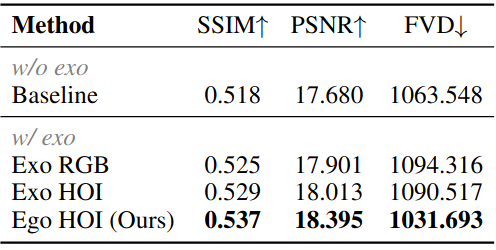
EgoExo-Gen将cross-view video prediction任务分解为cross-view learning(通过cross-view mask prediction model)和视频预测(通过HOI-aware video diffusion model)。我们修改了我们的模型,通过用原始的exo-centric RGB frames或exo-centric hand-object masks替换以ego-centric hand-object mask condition,从而能够将 exo-centric 信息整合到单个模型中。如下表所示,两种方法都获得了次优性能,表明在单个 video diffusion model中进行分类学习exo-ego translation 和视频预测的困难。相比之下,ego-centric的视图中的hand-object movement提供了明确的像素对齐视觉线索,以改善视频预测。
外部中心信息融入的比较。
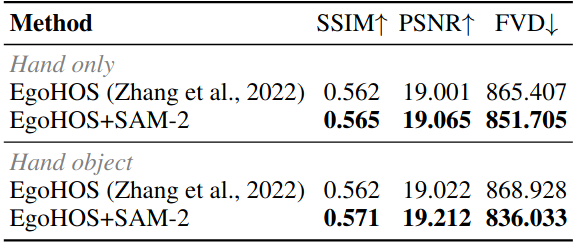
Analysis on data pipeline
为了验证我们的 cross-view mask 生成 pipeline 的效果,我们比较了仅在通过EgoHOS与EgoHOS+Sam-2生成的 HOI masks 上训练的视频预测模型。在这里,我们应用从未来帧提取的 HOI masks 作为直接比较的条件。EgoHOS执行每帧手部和交互对象分割,同时忽略随后帧之间的时间一致性。SAM 2通过在给定由EgoHOS生成的掩模提示的情况下在所有帧中跟踪手和对象来补偿时间一致性的损失。如下表所示,SAM-2 由于改善了hand and object masks 的质量而导致更好的生成性能。
注释pipline中HOI遮罩质量的比较。
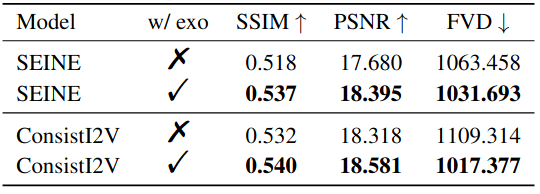
Application to different diffusion models
为了证明我们方法的概括能力,我们将我们的 cross-view mask prediction model 与不同的视频扩散模型集成。默认情况下,我们采用 SEINE 作为我们的主要视频传播模型。此外,我们还对 ConistI2V 进行了实验作为替代扩散模型,并且训练和推理 pipline 保持不变。实验结果如下表所示,这表明,结合交叉视图屏蔽预测模型可以在SEINE和ConstI2V上获得性能提升。这验证了我们的方法在不同视频扩散模型中引入交叉视图信息方面的概括能力。
EgoExo-Gen对不同视频预测模型的推广能力。
Quanlitative Comparision and Limitation
我们在下图中显示了预测视频的可视化结果。
定性比较。EgoExo-Gen(w/o future)指的是我们使用预测的HOI mask作为条件的默认模型。EgoExo-Gen(w/ future)使用从可见的未来帧(中提取的HOI masks,充当Oracle。最后一行显示了手部运动复杂的失败案例。
 我们的默认模型,即EgoExoGen(w/o future)预测具有合理手物体运动的视频,尽管需要轻微的手物体运动(例如,搅拌)。相比之下,ConistI 2 V可能会导致物体形状不稳定(例如,碗)或在第二种情况下几乎静态的视频。然而,我们发现 EgoExo-Gen 和 ConstI 2V 在涉及复杂手部运动的情况下都会失败,如最后一行所示。在第2列中,我们还展示了先验模型的结果,其中我们的HOI感知视频扩散模型采用使用EgoHOS和Sam-2从可见未来帧中提取的手对象面具。尽管存在上述挑战,EgoExo-Gen(w/ future)预测了接近地面真相的真实视频。
我们的默认模型,即EgoExoGen(w/o future)预测具有合理手物体运动的视频,尽管需要轻微的手物体运动(例如,搅拌)。相比之下,ConistI 2 V可能会导致物体形状不稳定(例如,碗)或在第二种情况下几乎静态的视频。然而,我们发现 EgoExo-Gen 和 ConstI 2V 在涉及复杂手部运动的情况下都会失败,如最后一行所示。在第2列中,我们还展示了先验模型的结果,其中我们的HOI感知视频扩散模型采用使用EgoHOS和Sam-2从可见未来帧中提取的手对象面具。尽管存在上述挑战,EgoExo-Gen(w/ future)预测了接近地面真相的真实视频。
这表明 EgoExo-Gen 中的 HOI-aware video diffusion model 学习了对手和物体的良好控制性,而性能受到 sub-optimal mask预测能力的限制。提高未来不可见帧中predicted masks的质量(例如,第10帧)将是我们未来的工作。
在可见的第1帧以及不可见的第5帧和第10帧处,exo-centric的 hand-object masks和预测的 ego-centric masks的可视化。

Related Work
Egocentric-Exocentric video understanding and generation
超越 ego-only的Wang等人; Pei等人或 exo-only 的Wang等人视频分析、从以ego-centric 和 exo-centric 的联合角度理解视频涵盖了广泛的任务,例如action recognition,retrieval、cross-view relation,以及skill assessment。虽然大多数作品在视频层面上执行跨视图动作理解,但另一条研究路线专注于跨视图翻译/生成,这需要在不同视图之间建立时空关系。例如,Luo等人提出了通过从自我中心视图中挖掘轨迹信息来生成外心视图。Luo等人通过探索手部姿势作为图像扩散模型的显式指导,实现了exo-to-ego 图像生成。与先前的方法相比,我们设计了一种cross-view mask prediction model,以预测手和交互对象从exo-view到ego-view的spatio-temporal masks。
Diffusion models for video prediction
视频预测(又名 图像动画)旨在以第一帧作为条件来生成后续视频帧。受text-to-image(T2I)diffusion models 的启发和 text-to-video(T2V)diffusion models ,一系列作品将第一帧作为T2V模型的附加条件,实现可控视频预测。ConsistI 2 V在第一帧中进行时空关注,以保持空间和运动一致性。DynamiCrafter设计了dual-stream image injection paradigm来改进生成。与之前专注于在一般领域生成视频的方法相比,通过分解text instructions来预测现实世界的 ego-centric 视频 或专用适配器。我们的工作明确地建模了dynamics(即hands and interacting objects)在 ego-centric的视频预测中。
Hand-Object segmentation
对手与物体交互(HOI)的分析涵盖了广泛的研究方向。在这里,我们重点关注hand and interacting object segmentation(HOS),这是一项具有挑战性的任务,需要模型来分割开放世界的交互对象。Visor和EgoHOS提议以ego-centric 视图分割左手/右手和交互对象。尽管表现出色,但这些作品在 exo-centric的视图上通常失败。为了以第三人称视角解决HOS问题,HOISTformer设计了一款 maskformer-based的在 exo-centric dataset上训练的手对象分割模型。最近专门用于分割的视觉基础模型、SAM-2 能够在视觉提示的情况下分割和跟踪对象。Sapiens(擅长分割人体部位,包括手和手臂。我们的自动化管道是建立在这些作品的基础上的,可以在自我和外部视图中分割手和物体。
Conclusion
在本文中,我们提出 EgoExo-Gen 通过对视频中的 hand-object dynamics进行建模来解决 cross-view video prediction 任务。EgoExo-Gen结合了
- 一个 cross-view mask prediction model,该模型通过建模spatio-temporal ego-exo correspondence 来估计未观察到的 ego-frames 的 hand-object masks;
- HOI-aware video diffusion model,该模型将结合预测的 HOI masks作为结构指导。
我们还设计了一个自动化的 HOI mask annotation pipeline,为ego- and exo-videos 生成 HOI mask,增强了EgoExo-Gen的可扩展性。实验证明,EgoExo-Gen在预测具有真实的hand-object movement的视频方面优于现有视频预测模型,揭示了其在AR/VR和 embodied AI 中的潜在应用。