Abstract
最近的研究探索了使用 diffusion transformers(DiT)通过简单地在图像之间 concatenating attention tokens 来生成 task-agnostic 图像。然而,尽管有大量的计算资源,生成的图像的保真度仍然不理想。在这项研究中,我们通过假设 text-to-image 的 DiT 固有地拥有 in-context generation 的能力,只需最低限度的调整即可激活它们,从而重新评估和简化了这个框架。通过不同的任务实验,我们定性地证明了现有的 text-to-image DiT可以在无需任何调整的情况下有效地执行上下文生成。基于这一见解,我们提出了一个非常简单的pipeline 来利用 DiT 的上下文能力:
- 连接图像而不是 tokens;
- 执行多个图像的 joint captioning;
- 使用小数据集应用特定于任务的LoRA调整(例如,20 ~ 100个样本),而不是对大型数据集进行全参数调优。
我们将我们的模型命名为 In-Context LoRA(IC-LoRA)。这种方法不需要修改原始 DiT 模型,只需要更改训练数据。值得注意的是,我们的 pipeline 可以生成更好地遵守提示的高保真图像集。虽然在调优数据方面是特定于任务的,但我们的框架在架构和管道方面仍然保持 task-agnostic,这为社区提供了强大的工具,并为进一步研究产品级任务不可知生成系统提供了有价值的见解。我们在 GitHub上发布我们的代码、数据和模型。
Introduction
文本到图像模型的出现显着推进了视觉内容生成领域,使能够从文本描述创建高保真图像。现在,许多方法都提供了对各种图像属性的增强控制,允许在生成期间进行更细的调整。尽管取得了这些进展,适应文本到图像的模型,以广泛的生成任务,特别是那些需要连贯的图像集与复杂的内在关系,仍然是一个开放的挑战。在这项工作中,我们介绍了一个 task-agnostic 的框架,旨在适应文本到图像模型,以不同的生成任务,旨在提供一个通用的解决方案,多功能和可控的图像生成。
传统方法(任务特定):要做图像分类,就训练一个分类网络(如ResNet)。要做目标检测,就训练一个检测网络(如Faster R-CNN)。要做语义分割,就训练一个分割网络(如U-Net);每个模型都是“各自为政”,从零开始或在特定数据集上微调,学到的特征只擅长自己的任务。
任务无关的方法:先使用一种通用的、自监督的预训练方法(如MAE, SimCLR, DINO)在一个巨大的、无标签的图像库(如ImageNet)上训练一个模型。这个模型学习到的图像特征就是“任务无关”的。它不知道也不关心你将来要用它来分类、检测还是分割。它只是学会了如何很好地“理解”图像的内容和结构。当需要解决具体任务时,只需在这个通用的“任务无关”模型后面添加一个非常简单的任务特定头(比如一个分类层),然后用少量数据进行微调,甚至不微调(线性探测),就能取得非常好的效果。
任务无关的框架是一个系统或模型架构,它被设计成能够不经过核心结构修改,直接处理多种不同的视觉任务。这个框架的核心是一个共享的、任务无关的骨干网络,它负责从图像中提取通用的特征。然后,通过附加不同的、轻量级的“任务头”或使用不同的提示指令,来引导这个骨干网络解决不同的问题。
最近的工作,例如 Group Diffusion Transformers(GDT)框架,探索了将视觉生成任务重新定义为群体生成问题。在这种情况下,具有任意 intrinsic relationships 的一组图像在单个去噪扩散过程中同时生成,可选地以另一组图像为条件。GDT 的核心思想是将图像中的注意力标记连接起来,包括条件标记和要生成的标记,同时确保每个图像的标记只关注其相应的文本标记。这种方法允许模型以与任务无关的零触发方式适应多个任务,而无需任何微调或梯度更新。
然而,尽管 GDT 具有创新的架构,但其generation fidelity 相对较低,与原始预训练的文本到图像模型相比,通常表现不佳。这一限制促使人们重新审视将文本到图像模型适应复杂生成任务时所采用的基本假设和方法。
在这项工作中,我们做出了一个关键假设:text-to-image 模型固有地拥有in-context generation capabilities 。为了验证这一点,我们直接将现有的 text-to-image 模型应用于各种需要生成具有不同关系的图像集的任务。如图3所示;
FLUX文本到图像生成示例。使用 FLUX.1-dev 跨六个任务生成文本到图像的示例,突出显示了具有不同关系属性的多面板图像的创建。主要观察结果包括:(1)原始的文本到图像模型已经可以生成在身份、风格、照明和字体方面具有连贯一致性的多面板输出,尽管仍然存在一些小的缺陷。(2)FLUX.1-dev在解释描述多个面板的组合提示方面表现出强大的能力。

以 FLUX.1-dev 模型为例,我们观察到该模型已经可以执行不同的任务,尽管存在一些缺陷。它保持一致的属性,例如对象身份、风格、照明条件和调色板,同时修改姿势、3D方向和布局等其他方面。此外,该模型还展示了在单个合并提示内解释和遵循多个图像描述的能力。
这些令人惊讶的发现让我们得到了几个关键见解:
- 固有上下文学习:文本到图像模型已经具备上下文生成能力。通过适当触发和增强这种能力,我们可以利用它来执行复杂的生成任务。
- 无需架构修改的模型可重用性:由于 text-to-image 模型可以解释合并的captions,因此我们可以重用它们在上下文中生成,而无需对其架构进行任何更改。这涉及简单地更改输入数据,而不是修改模型本身。
- 最少数据和计算的效率:无需大型数据集或延长训练时间即可实现高质量的结果。小型、高质量的数据集加上最少的计算资源可能就足够了。
基于这些见解,我们设计了一个极其简单但有效的 pipeline,用于使 text-to-image 模型适应不同的任务。我们的方法在以下方面与 GDT 形成鲜明对比:
- 图像拼接:我们将一组图像拼接成单个大图像,而不是拼接注意力标记。该方法大致相当于 diffusion transformers(DiT)中的 token concatenation,忽略了 Variational Autoencoder(VAE)组件引入的差异。
- prompts 拼接:我们将每个图像的 prompts 合并为一个长prompt,使模型能够同时处理和生成多个图像。这与 GDT 方法不同,在GDT方法中,每个图像的 tokens 都与其文本 tokens 交叉。
- 使用小数据集进行最小微调:我们没有对数十万个样本进行大规模训练,而是使用一小组仅 个图像集来微调模型的 Low-Rank Adaptation(LoRA)。这种方法显着减少了所需的计算资源,并在很大程度上保留了原始文本到图像模型的知识和上下文能力。
生成的模型非常简单,不需要修改原始的 text-to-image 模型。调整仅通过根据特定任务需求调整一小组调整数据来实现。为了支持image-conditional generation,我们采用了一种简单的技术:在连接的大图像中 mask 一个或多个图像,并 prompt 模型使用剩余图像修补它们。为此,我们直接利用SDEDit。
尽管它的简单性,我们发现,我们的方法可以适应各种各样的高质量的任务。虽然我们的方法需要特定于任务的调优数据,但整体框架和 pipeline 仍然与任务无关,允许在不修改原始模型架构的情况下适应各种任务。这种最低数据要求和广泛适用性的结合为生成社区,设计师和艺术家提供了强大的工具。我们承认,开发一个完全统一的发电系统仍然是一个开放的挑战,并将其作为未来的工作。为了便于进一步研究,我们在项目页面2发布了我们的数据、模型和训练配置。
Related Work
Task-Specific Image Generation
Text-to-image 模型在从复杂的文本提示生成高保真图像方面取得了显着的成功。然而,它们通常缺乏对生成图像的特定属性的细粒度可控性。为了解决这一限制,人们提出了许多工作来增强对布局等方面的控制和照明条件。有些方法甚至支持同时生成多个图像,类似于我们的方法。
尽管取得了这些进步,但这些模型通常采用特定于任务的架构和 pipelines,限制了它们的灵活性和通用性。每个架构都是针对单个任务量身定制的,并且为一项任务开发的功能不容易组合或扩展到任意新任务。这与自然语言处理的最近进展形成鲜明对比,其中模型被设计为在单个体系结构中执行多个任务,并且可以概括超出它们显式训练的任务。
Task-Agnostic Image Generation
为了克服任务特定模型的限制,最近的研究旨在创建任务不可知的框架,该框架支持单个架构内的多个可控图像生成任务。例如,Emu Edit 集成了广泛的图像编辑功能,而Emu 2,TransFusion ,和 OmniGen 在一个统一的模型中执行不同的任务,从 procedural drawing 到 subject-driven generation。Emu 3通过在一个框架下支持文本、图像和视频生成进一步扩展了这一功能。这些工作代表了统一或任务不可知的一代的实质性进展。
与这些模型相反,我们提出现有的 text-to-image 架构已经具备内在的上下文能力。这消除了开发新架构的需要,并以最少的额外数据和计算资源实现高质量生成。我们的方法不仅提高了效率,而且还在各种任务中提供卓越的发电质量。
Method
Problem Formulation
遵循 Group Diffusion Transformers 的方法[Huang等人,2024],我们将大多数图像生成任务定义为产生一组 图像,条件是另一组图像和个文本提示。该形式化涵盖广泛的学术任务,例如图像翻译、风格转移、姿势转移和主题驱动生成,以及图画书创作、字体设计和转移、故事板生成等实际应用。条件图像和生成的图像之间的相关性通过每个图像提示隐式地维护。
我们的方法通过对整个图像集使用一个consolidated prompt 来稍微修改这个框架。此 prompt 通常从图像集的总体描述开始,然后是每个图像的单独提示。这种统一的 prompt 设计与现有的 text-to-image 模型更兼容,并允许整体描述自然地传达任务的意图,就像客户如何向艺术家传达设计要求一样。
Group Diffusion Transformers
我们从基本框架开始,Group Diffusion Transformers(GDT)。在GDT中,通过在每个 Transformer self-attention block 中的图像之间连接 attention tokens,在单个扩散过程中同时生成一组图像。这种方法使每个图像都能够“看到”集中的所有其他图像并与其交互。Text conditioning 是通过让每个图像注意其相应的 text embeddings 来引入的,使其能够访问其他图像的内容和相关的 text guidance。 GDT在数十万个图像集上训练,使其能够以零镜头方式在任务中进行概括。
In-Context LoRA
虽然 GDT 展示了零镜头任务适应性,但其生成质量不足,与text-to-image models模型的 baseline 相比,通常表现不佳。我们提出了一些改进措施来改进这个框架。
我们的出发点是假设基础的 text-to-image 模型固有地拥有一些针对不同任务的上下文生成能力,即使质量有所不同。下图中的结果支持了这一点,其中模型有效地生成跨不同任务的多个图像(有时有条件)。
FLUX文本到图像生成示例。使用 FLUX.1-dev 跨六个任务生成文本到图像的示例,突出显示了具有不同关系属性的多面板图像的创建。主要观察结果包括:(1)原始的文本到图像模型已经可以生成在身份、风格、照明和字体方面具有连贯一致性的多面板输出,尽管仍然存在一些小的缺陷。(2) FLUX.1-dev在解释描述多个面板的组合提示方面表现出强大的能力,详情请在附录A中。
基于这一见解,不需要对大型数据集进行广泛的训练;我们可以通过精心策划的高质量图像集激活模型的上下文能力。
另一个观察结果是,text-to-image 模型可以从包含多个面板描述的单个 prompt 生成连贯的 multi-panel 图像。
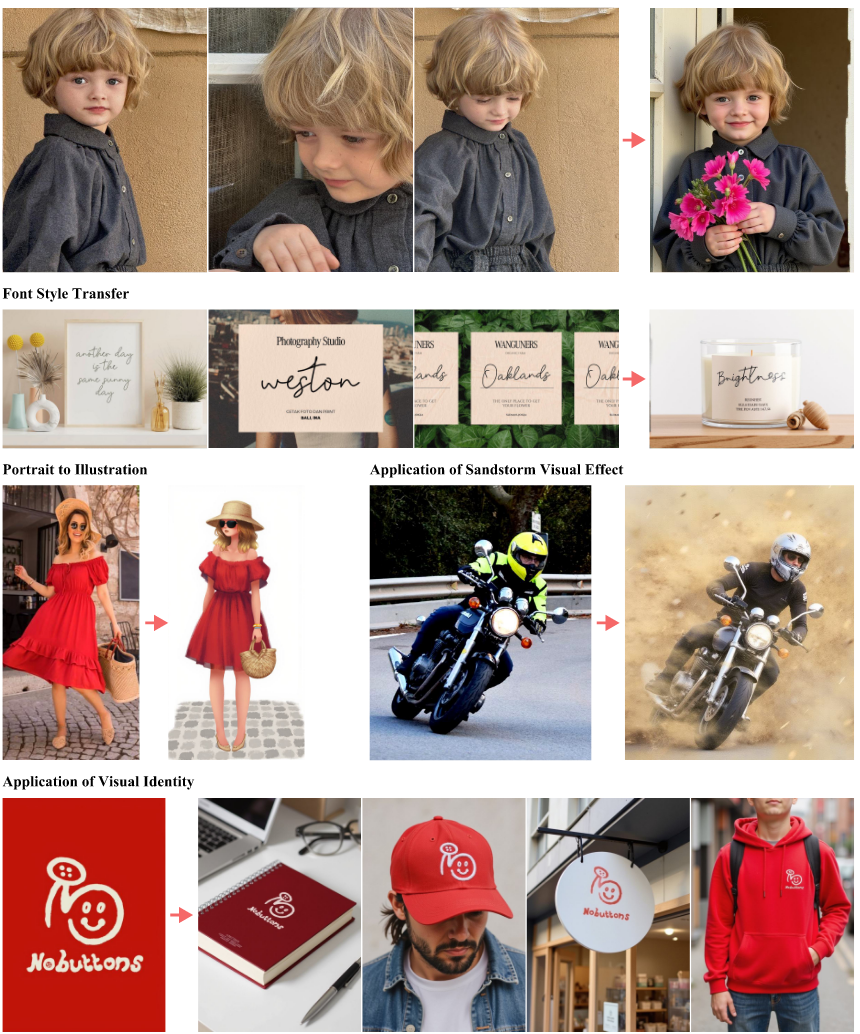
1 | (a) Portrait Photography. This four-panel image captures a young boy’s adventure in the woods, expressing curiosity and wonder. [TOP-LEFT] He crouches beside a stream, peering intently at a group of frogs jumping along the rocks, his face full of excitement; [TOP-RIGHT] he climbs a low tree branch, arms stretched wide as he balances, a big grin on his face; [BOTTOM-LEFT] a close-up shows him kneeling in the dirt, inspecting a bright yellow mushroom with fascination; [BOTTOM-RIGHT] the boy runs through a clearing, his arms spread out like airplane wings, lost in the thrill of discovery. |
因此,我们可以通过使用统一的图像提示来简化架构,而不是要求每个图像专门关注其各自的文本标记。这使我们能够重复使用原始的 text-to-image架构,而无需进行任何结构上的修改。
我们最终的框架设计通过在训练期间将一组图像直接连接成一个大图像,同时生成一组图像,同时将它们的 captions 合并成一个合并的 prompt,并为每个面板提供总体描述和明确的指导。生成图像集后,我们将大图像拆分为各个面板。此外,由于 text-to-image 模型已经展示了上下文能力,因此我们不会对整个模型进行微调。相反,我们对一小群高质量数据应用Low-Rank Adaptation(LoRA)来触发和增强这些功能。
Low-Rank Adaptation(LoRA, 大模型的低秩自适应) 是一种用于高效微调大型预训练模型(如GPT、扩散模型、BERT等)的技术。
- 传统微调:好比为了给一件西装换个款式,你把整件衣服拆了,重新裁剪缝合所有布料。这需要很高的手艺(计算资源)和很长时间,而且容易把原来的好布料(预训练中获得的知识)弄坏。
- LoRA微调:好比在这件西装的关键部位(比如肩部、腰部)用别针固定上几块小小的、新的布料。这些小块布料专门用于调整款式,非常轻便,而且随时可以取下,恢复西装原样。
LoRA基于以下假设:模型在适应新任务时,其权重变化具有“低秩”特性。这意味着不需要一个完整的、高维度的矩阵来表示所有的变化,而是可以用两个更小、更薄、可训练的矩阵的乘积作为旁路近似这个变化。在微调过程中,只更新A和B这两个小矩阵的参数,原始权重保持不变。矩阵A和B的秩非常小,这使得它们包含的参数数量极少
- 矩阵负责将输入数据降维;
- 矩阵负责将降维后的数据再升维回原始维度;
- 原始模型微调为;
为了支持对额外图像集的条件处理,我们使用 SDEDit(一种免训练方法)来基于 unmasked set 来修补一组图像,所有图像都连接在单个大图像中。
Stochastic Differential Editing(SDEdit, 随机微分编辑) 是一种Diffusion Model-based、train-free的图像生成与编辑方法。可以理解为一种模糊重绘技术:先给输入图像添加噪声,使其变模糊,然后利用 Diffusion Model,在降噪过程中重新绘制出一张既符合你输入的结构、又逼真自然的新图像。
Experiments
Implementation Details
我们在 FLUX.1-dev text-to-image 模型上构建我们的方法,并专门针对我们的任务训练 In-Context LoRA。我们选择一系列实用的任务,包括storyboard generation、font design、portrait photography、visual identity design、home decoration、visual effects、portrait illustration和 PowerPoint template design等。对于每个任务,我们从互联网上收集 20 到 100 个高质量图像集。每一组都连接成一张合成图像,并使用 Multi-modal Large Language Models (MLLMs) 生成这些图像的字幕,首先是总体摘要,然后是每个图像的详细描述。训练在单个A100 GPU上进行,执行 5000 个步骤,批量大小为4,LoRA秩为 16。为了进行推断,我们采用了 20 个抽样步骤,指导标度为3.5,与 FLUX.1-dev 的蒸馏指导标度相匹配。对于图像条件生成,SDEDdit应用于旨在生成的 mask images,从而能够基于周围图像进行修补。
Results
我们提供定性结果,证明我们的模型在各种任务中的通用性和质量。鉴于任务的多样性,我们推迟对未来的工作采用统一的,定量的 benchmark 和评估。
Reference-Free Image-Set Generation
在此设置中,图像集仅根据文本提示生成,无需额外的图像输入。我们的方法在一系列图像集生成任务中实现了高质量的结果。
Reference-Based Image-Set Generation
在此设置中,使用 text prompt 和输入图像集 具有至少一个参考图像 生成图像集。SDEDdit用于 mask 某些图像,从而启用基于其余图像的修复。图像条件生成的结果如图13所示,常见的失败案例如图14所示。
图像条件生成。在多个任务中使用In-上下文LoRA以及免训练SDEDit的图像条件生成示例。在某些情况下,例如沙尘暴视觉效果的应用案例,输入和输出图像之间可能会出现不一致,包括汽车驾驶员身份和着装的变化。解决这些不一致之处留给未来的工作。
图像条件生成的失败案例。使用带SDEDit的In-Context LoRA的肖像身份传输失败的示例。我们观察到 In-Context LoRA 的 SDEDdit 往往不稳定,通常无法保留身份。这可能源于 SDEDdit对输入到输出映射的单向依赖性与 In-Context LoRA 训练的双向性质之间的差异。解决这个问题留给未来的工作。

尽管在多个任务中有效,但与文本条件生成相比,图像之间的视觉一致性有时较低。这种差异可能是由于SDEDit在掩蔽和未掩蔽图像之间的单向依赖性造成的,而纯文本生成允许图像之间的双向依赖性,从而实现条件和输出的相互调整。这表明了改进的潜力,例如结合可训练的修复方法,我们将其留给未来的探索。
Reproducing
克隆 ai-toolkit 仓库和 In-Context-LoRA 仓库;
1 | git clone https://github.com/ostris/ai-toolkit.git /opt/liblibai-models/user-workspace2/model_zoo |
创建虚拟环境
1 | conda create -n aitk_xqy python=3.11 |
在命令行下登陆 Huggingface;
1 | huggingface-cli login |
移动配置文件
1 | scp /opt/liblibai-models/user-workspace2/model_zoo/In-Context-LoRA/config/movie-shots.yml /opt/liblibai-models/user-workspace2/model_zoo/ai-toolkit/config/ |
执行训练
1 | cd /opt/liblibai-models/user-workspace2/model_zoo/ai-toolkit |
可以看到加载了配置文件进行训练;
或者使用 UI 进行训练的配置,注意
-
在本地访问
http://localhost:8675,在服务器上执行如下命令(这个命令是可以中断的,无需保持 UI 运行即可运行作业,它只需要启动/停止/监控作业。)1
2cd ui
npm run build_and_start -
修改配置文件,指定 FLUX 模型为本地已经下载好的模型,而不是从 Huggingface 拉取;
1
2
3
4model:
name_or_path: "/opt/liblibai-models/user-workspace2/model_zoo/FLUX.1-dev"
is_flux: true
quantize: true -
(opt) 开始训练前,在 Huggingface 上获取 Access Tokens;
训练的 UI 界面如下: