Abstract
我们展示了 FLUX.1 Kontext 的评估结果,这是一种统一图像生成和编辑的生成式流匹配模型。该模型通过结合文本和图像输入的语义上下文来生成新颖的输出视图。FLUX.1 Kontext 使用简单的序列级联方法,在单一统一架构内处理本地编辑和生成性上下文任务。与当前在多个回合中显示字符一致性和稳定性下降的编辑模型相比,我们观察到 FLUX.1 Kontext 改进了对象和字符的保存,导致迭代工作流程的鲁棒性更强。该模型通过当前最先进的系统实现了有竞争力的性能,同时提供了显着更快的生成时间,支持交互式应用程序和快速原型制作工作流程。为了验证这些改进,我们引入了 KontextBench ,这是一个综合基准测试,包含 1026 个图像提示对,涵盖五个任务类别:本地编辑、全局编辑、字符引用、样式引用和文本编辑。详细的评估表明,FLUX.1 Kontext 在 single-turn 质量和 multi-turn 一致性方面都表现出色,为统一图像处理模型树立了新标准。
Introduction
图像是现代传播的基础,也是社交媒体、电子商务、科学可视化、娱乐和模因等各个领域的基础。随着视觉内容的数量和速度的增加,对直观但忠实和准确的图像编辑的需求也在增加。用户期望工具能够保留精细细节、保持语义一致并更多的响应自然语言命令。大规模生成模型的出现改变了这种格局,实现了以前不切实际或不可能的纯文本驱动图像合成和修改。
传统的图像处理 pipelines 通过直接操纵像素值或通过在显式用户控制下应用几何和光学变换来工作。相比之下,generative processing 使用深度学习模型及其学习的 representations 来合成无缝适应新场景的内容。两种互补的能力是该范式的核心
-
Local editing:局部、有限的修改,以保持周围环境完整
-
例如,改变汽车的颜色,同时保留背景,或替换背景,同时将主题保持在前景。
-
LaMa 、Latent Diffusion inpainting、RePaint 、Stable Diffusion Inpainting variants 和 FLUX.1 Fill 3等生成性修复系统使此类上下文感知编辑变得即时;
-
除了修补之外,ControlNet 还支持面具引导的背景替换,而 DragGAN 提供交互式的基于点的几何操纵。
-
-
Generative editing:提取视觉概念(例如特定的人物或标志),然后在新环境中忠实再现,可能在新的视角下合成或在新的视觉环境中渲染。
- 与大型语言模型中的 in-context learning 类似,其中网络从提示中提供的示例中学习任务,而无需任何参数更新,生成器将其输出动态地适应条件上下文。
- 该属性可以实现生成图像和视频模型的个性化,而无需微调或 LoRA 训练。
- 此类免训练主题驱动图像合成的早期工作包括 IP-Adapter 或 retrieval-augmented diffusion variants。
最近的进展
DirectPix2Pix 和后续工作展示了 synthetic instruction-response pairs 对微调 diffusion mode(用于图像编辑)的前景,而个性化 text-to-image synthesis 的 learning-free 方法使 image modification 能够使用脱离现实的高性能图像生成模型。
后续的 instruction-driven editors (例如Emu Edit, OmniGen, HiDream-E1, ICEdit) 将这些想法扩展到细化的数据集和模型架构。Huang等人在特定任务上引入了针对 diffusion transformers 的上下文 LoRA,其中每个任务都需要训练专用的LoRA 权重。嵌入在 multimodal LLMs (例如,GPT-Image, Gemini Native Image Gen)中的 新型的 proprietary systems 进一步模糊了对话框和编辑之间的界限。
Midjourney 和 RunwayML 等生成性平台将这些进步集成到端到端创意工作流程中。
最近方法的缺点
就结果而言,目前的方法存在三大缺陷:
- instruction-based 的方法在 synthetic pairs 上训练,继承了其 generation pipelines 的缺点,限制了可实现编辑的多样性和真实性;
- 在多次编辑中保持角色和对象的准确外观仍然是一个悬而未决的问题,阻碍了讲故事和品牌敏感应用程序;(人物一致性存在问题)
- 与 denoising-based 方法相比,除了质量较低之外,集成到大型多模式系统中的自回归编辑模型通常具有较长的运行时间,与交互式使用不兼容。
解决方案
我们引入了FLUX.1 Kontext,这是一种 flow-based 生成式图像处理模型,其质量相匹配或超过最先进的黑匣子系统,同时克服了上述限制。
FLUX.1 Kontext是一个简单的流匹配模型,仅使用 context 和 instruction tokens 的 concatenated sequence上的速度预测目标 进行训练。
- Character consistency :FLUX.1 Kontext 擅长 character preservation,包括多次迭代的edit turns。
- Interactive speed :FLUX.1 Kontext 速度快。文本到图像和图像到图像应用程序都能达到1024 x 1024(3-5秒)的图像合成速度。
- Iterative application:快速推理和强大的一致性使用户能够通过多次连续编辑以最小的视觉漂移来细化图像。
FLUX.1
FLUX.1是一类 rectified flow transformer,使用 image autoencoder 的潜在空间训练。我们跟随 Rombach et al,从头开始训练具有对抗目标的 convolutional autoencoder。
- 通过扩大训练计算并使用16个潜在 channels,与相关模型相比,我们提高了重建能力;
- 此外,FLUX.1 是由 double stream blocks 和 single stream blocks 的 mixing 构建的。
- double stream blocks 对图像和文本标记采用单独的权重;
- mixing 是通过对 tokens 串流使用 attention operation 来完成的。
- 在将 tokens 串流传递通过 double stream blocks 后,我们将它们连接起来,并将38个 single stream blocks 应用于图像和文本标记。
- 最后,我们丢弃文本标记并解码图像标记。
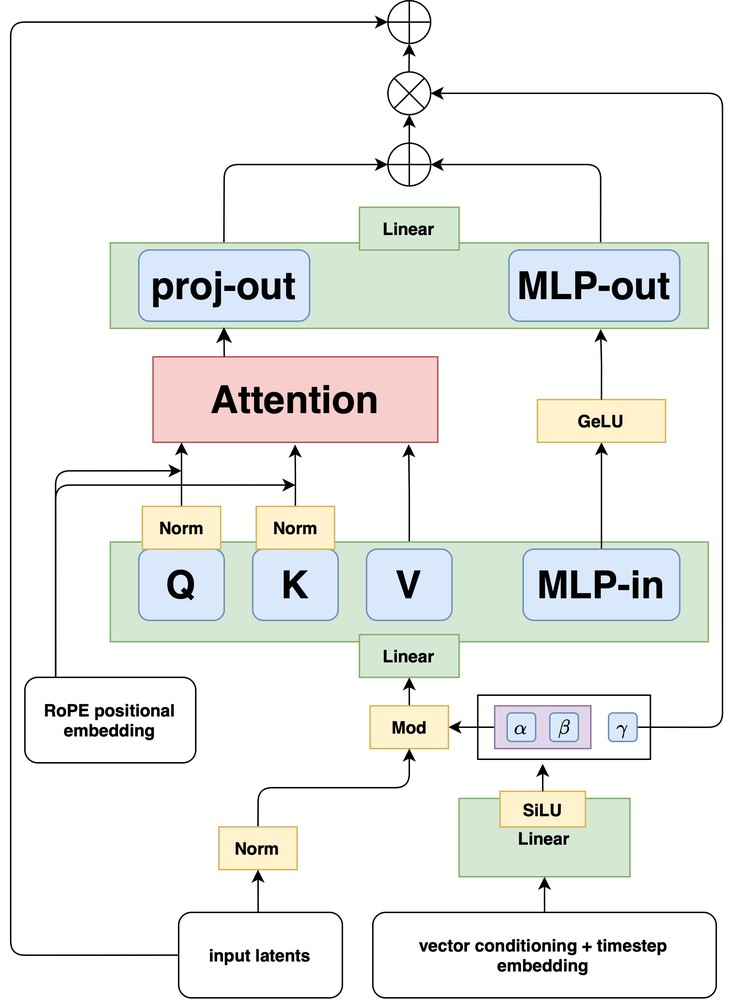
为了提高 single stream blocks 的 GPU 利用率,我们利用了受 Dehghani 等人启发的融合feed-forward blocks
- 将 feed-forward blocks 中的调制参数数量减少2倍
- 将注意力输入和输出线性层与 MLP 的融合,从而产生更大的 matrix-vector multiplications,从而提高训练和推理效率。
- 我们利用 factorized 3D RoPE。每个 latent token 都由其时空坐标 来索引(对于单个图像输入,)。
FLUX.1 Kontext
我们的目标是学习一种可以根据 text prompt 和参考图像共同生成图像的模型。更正式地说,我们的目标是逼近条件分布
- 是目标图像;
- 是上下文图像(或上下文图像);
- 是自然语言指令;
与经典的文本到图像生成不同,这个目标需要学习图像本身之间的关系,由 介导,以便同一个网络可以
- 当 时执行图像驱动的编辑,
- 当 时从头开始创建新内容。
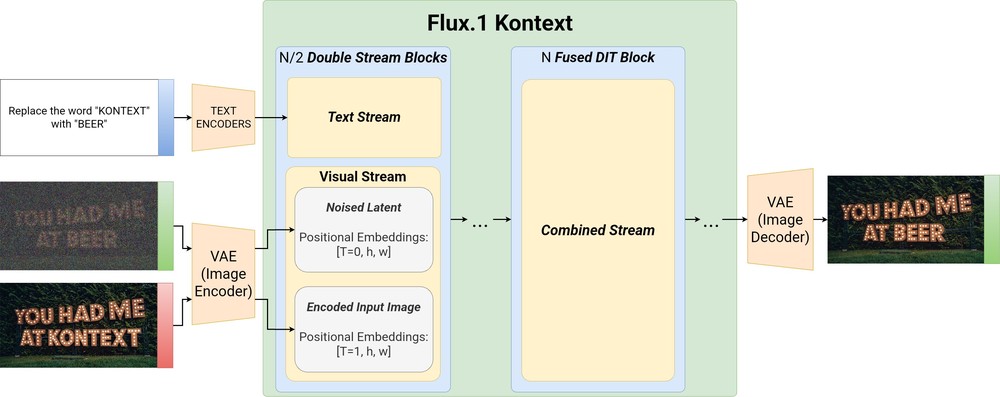
为此,令 是输出(目标)图像, 是可选的上下文图像, 是文本提示。我们对条件分布 建模,以便对于同一个网络当 执行 in-context and local edits ,以及当 时执行 free text-to-image generation。训练从 FLUX.1文本到图像的 checkpoint开始,我们收集并策划数百万个关系对 用于优化。实际上,我们不会在 pixel space 中对图像进行建模,而是将它们编码为 token sequence。
Token sequence construction
图像通过冻结的 FLUX autoencoder 编码成 latent tokens。然后,这些上下文图像 tokens 被append 到图像 token ,并被馈送到模型的 visual stream 中。这种简单的 sequence concatenation
- 支持不同的输入/输出分辨率和宽高比
- 容易扩展到多个图像 。
我们还测试了和的逐行级联,但在最初的实验中,我们发现这种设计选择的性能更差。
我们通过3D RoPE嵌入来编码位置信息,其中上下文 的 embeddings 接收所有上下文 token 的 constant offset 。我们将 offset 视为一个虚拟时间步,它将 context 和target blocks 干净地分开,同时保持其内部空间结构不变。具体来说,如果 token position 由元组 表示,那么我们为 target tokens 设置和为 context tokens 设置 ;
Rectified-flow objective
我们训练采用 rectified flow–matching loss
其中 是 和噪音之间的线性插值隐变量;
我们对 使用 logit normal shift schedule,其中我们根据训练期间数据的分辨率更改模式 。当对 text–image pairs() 进行采样时,我们忽略所有tokens ,以保留模型的文本到图像生成能力。
Adversarial Diffusion Distillation
通过优化 rectified flow–matching loss 获得的流匹配模型的采样通常涉及使用50-250个 guided network evaluations 来求解普通或随机方程。虽然通过这样的过程获得的样本对于 well-trained model 来说质量良好,但这也存在一些潜在的缺点:
- 这种多步采样速度慢,导致模型大规模服务成本高昂,并阻碍了低延迟、交互式应用程序。
- 此外,指导偶尔可能会引入视觉伪影,例如过饱和样本。
我们使用 latent adversarial diffusion distillation(LADD)来应对这两个挑战,减少采样步骤的数量,同时通过对抗训练提高样本质量。
Implementation details
从纯粹的文本到图像检查点开始,我们按照 rectified flow–matching loss 顺带地对 image-to-image 和 text-to-image 任务上的模型进行微调。虽然我们的公式自然涵盖了多个输入图像,但我们目前专注于单个背景图像进行条件反射。
FLUX.1 Kontext [pro]使用 flow objective 和LADD 进行训练。我们按照Meng等人中概述的技术,通过引导蒸馏到12B diffusion transformer 中来获得 FLUX.1 Kontext [dev]。为了优化 FLUX.1 Kontext [dev] 编辑任务的性能,我们只关注 image-to-image 训练,即不训练 FLUX.1 Kontext [dev] 的text-to-image 任务。
我们采用了安全训练的操作,包括 classifier-based filtering 和 adversarial training,以防止产生non-consensual intimate imagery(NCII)和 child sexual abuse material(CSAM)。
我们以混合精度使用FSDP 2,all-gather operations 采用 bfloat 16中执行,而 gradient reduce-scatter 使用 float 32以提高数值稳定性。我们使用 selective activation checkpointing 以减少VRAM 的最大使用量。为了提高吞吐量,我们使用Flash Attention 3 和各个Transformer块的区域编译。
Evaluations & Applications
在本节中,我们将评估 FLUX.1 Kontext 的性能并展示其功能。我们首先介绍 KontextBench,这是一个 novel benchmark,其特点是现实世界的图像编辑挑战,这来自用户的众包。然后,我们提出了我们的主要评估:FLUX.1 Kontext 与最先进的 text-to-image 和 image-to-image 合成方法的系统比较,我们在不同的编辑任务中展示了具有竞争力的性能。最后,我们探讨了FLUX.1 Kontext的实际应用,包括迭代编辑工作流程,样式传输,视觉提示编辑和文本编辑。
KontextBench – Crowd-sourced Real-World Benchmark for In-Context Tasks
在捕捉现实世界的使用情况时,用于 editing models 的现有 benchmarks 通常受到限制。INSTPix 2 Pix 依赖于合成的 Stable Diffusion 样本和 GPT-generated 指令,从而产生固有的偏差。MagicBrush 虽然使用真实的 MS-COCO 图像,但在数据收集期间受到 DALLE-2 功能的限制。Emu-Edit 等其他基准使用具有不切实际分布的低分辨率图像,并且仅关注编辑任务,而 DreamBench 缺乏广泛的覆盖范围,Gedit-bridge 并不代表现代多模式模型的全部范围。Intelligence Bench仍然不可用,只有300个不确定任务覆盖的示例。
为了解决这些差距,我们从众包的现实世界用例中编篡了 KontextBench。该基准包括1026个独特的 image-prompt pairs,这些图像来自108个基本图像,包括个人照片、CC许可的艺术品、公共领域图像和人工智能生成的内容。它涵盖五项核心任务:local instruction editing(416)、global instruction editing(262)、text editing(92)、style reference(63)和character reference (193)。我们发现 benchmark的规模在可靠的人工评估和对现实世界应用程序的全面覆盖之间提供了良好的平衡。我们将发布此 benchmark,包括 FLUX.1 Kontext 的样本和所有报告的 baselines。
State-of-the-Art Comparison
FLUX.1 Kontext 旨在执行 text-to-image (T2I) 和image-to-image (I2I) 合成。我们根据这两个领域中最强大的专有和开放权重模型来评估我们的方法。我们评估FLOX.1 Kontext [pro]和[dev]。如上所述,对于[dev]来说,我们专门关注图像到图像的任务。此外,我们还引入了FLOX.1 Kontext [max],它使用更多计算来提高生成性能。
Image-to-Image Results
对于图像编辑评估,我们评估多个编辑任务的性能:图像质量、本地编辑、字符参考(Cref)、风格参考(Sref)、文本编辑和计算效率。
Cref 可以在新颖的设置中一致地生成特定的字符或对象,而Sref则允许从参考图像转移风格,同时保持语义控制。
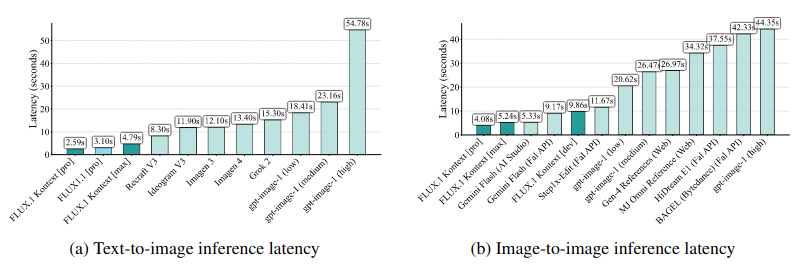
我们比较了不同的 API ,发现我们的模型提供了最快的延迟,在速度差异方面比相关模型表现高出一个数量级。在我们的人工评估中,我们发现 FLUX.1 Kontext [max]和[pro] 是本地和文本编辑类别以及一般 Cref 的最佳解决方案。我们还计算Cref的量化分数,为了评估输入和输出图像之间面部特征的变化,我们使用AuraFace 6来提取前后的面部嵌入,并编辑和比较两者。与我们的人类评估一致,FLOX.1 Kontext 优于所有其他模型。对于全局编辑和 Sref 来说,FLOX.1 Kontext分别仅次于gtt-Image-1和Gen-4 Reference。 总体而言,FLOX.1 Kontext提供了最先进的角色一致性和编辑功能,同时在速度上比GPT-Image-1等竞争模型要好一个数量级。
跨模型1024 x 1024生成的中位数推断延迟 秒 越低越好 FLOX.1 Kontext 在文本到图像和图像到图像任务方面都实现了有竞争力的速度
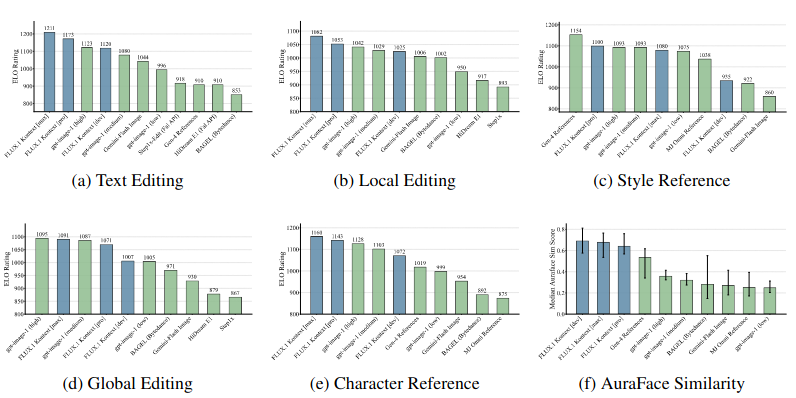
 KontextBench上的图像到图像评估 我们显示了六个上下文图像生成任务的评估结果。FLOX.1 Kontext pro 在所有任务中始终名列前茅 在文本编辑和字符保留方面取得了最高分
KontextBench上的图像到图像评估 我们显示了六个上下文图像生成任务的评估结果。FLOX.1 Kontext pro 在所有任务中始终名列前茅 在文本编辑和字符保留方面取得了最高分
Text-to-Image Results
当前的 T2I 基准主要关注一般偏好,通常会提出“which image do you prefer?”等问题。我们观察到,这种广泛的评估标准通常倾向于典型的“人工智能美学”,即过度饱和的色彩、过度关注中心主题、明显的散景效应以及向同质风格的趋同。我们将这种现象称为 bakeyness。
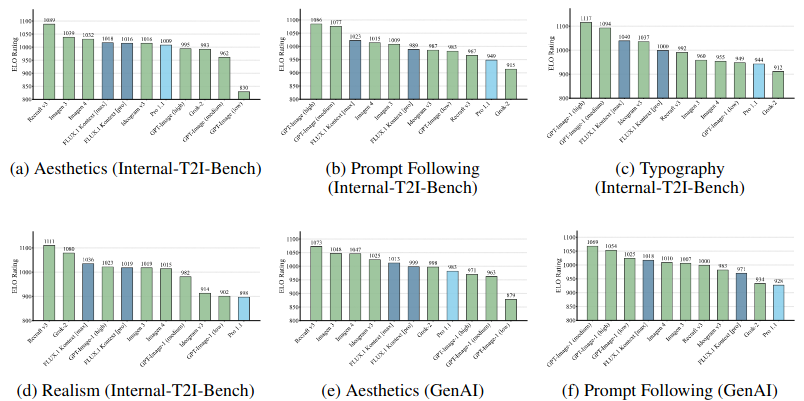
为了解决这一局限性,我们将T2 I评估分解为五个不同的维度:提示跟随、美观(“which image do you find more aesthetically pleasing”)、现实主义(“which image looks more real”)、印刷准确性和推理速度。我们评估了从学术基准(DrawBench,Participants)和真实用户查询中编译的1000个不同的测试提示。在下文中,我们将此基准称为 Internal-T2 I-Bench。此外,我们通过对GenAI工作台的额外评估来补充该基准。
在T2 I中,FLUX.1 Kontext在各个评估类别中表现出均衡的性能。尽管竞争模型在某些领域表现出色,但这往往以牺牲其他类别为代价。例如,Recraft提供了很强的美观质量,但及时的粘附性有限,而GPT-Image-1则显示出相反的整体性能模式。
FLUX.1 Kontext 与其前身 FLUX1.1 [pro] 相比,始终如一地提高了各个类别的性能。我们还观察到从FLUX.1 Kontext [pro]到FLUX.1 Kontext [max]的渐进收益。
Text-to-image evaluation on Internal-t2i-bench 我们报告多个质量维度的评估结果。FLOX.1 Kontext模型展示了美学、提示跟随、印刷和现实主义基准方面的竞争性能。
我们在下图中突出显示了样本。

Iterative Workflows
在多次编辑中保持角色和对象一致性对于品牌敏感和讲故事的应用程序至关重要。当前最先进的方法存在明显的视觉漂移:每次编辑,角色都会失去身份,对象都会失去定义性特征。在图12中,我们展示了由 FLUX.1 Kontext、Gen-4 和 GPT-Image-High 产生的编辑序列之间的字符身份漂移。我们还计算了输入和通过连续编辑生成的图像之间 AuraFace 嵌入的 cos 相似性,强调了FLUX.1 Kontext相对于竞争方法的较慢漂移。一致性至关重要:营销需要稳定的品牌特征,媒体制作需要资产连续性,电子商务必须保留产品细节。下图显示了由FLUX.1启用的应用Kontext的可靠的一致性。
迭代的产品风格编辑 从参考碗(a)开始,我们的模型首先在桌面工作室环境中生成一个与鲜花相匹配的花瓶(b),然后将花瓶的基本色更改为黑色,同时保留花卉图案、灯光和构图(c)
 连续的面部表情编辑 从轮廓参考(a)开始,我们的模特首先将对象重新定位为相机(b),然后将她的表情改变为自发的笑声(c),同时保留背景、服装和灯光
连续的面部表情编辑 从轮廓参考(a)开始,我们的模特首先将对象重新定位为相机(b),然后将她的表情改变为自发的笑声(c),同时保留背景、服装和灯光

Specialized Applications
FLUX.1 Kontext支持标准代以外的多个应用程序。风格引用(Sref)首先由Midjourney 普及,通常通过IP Adapters 实现,它可以从参考图像传输风格,同时保持语义控制。此外,该模型支持通过视觉线索进行直观编辑,响应红色椭圆等几何标记来指导有针对性的修改。它还提供复杂的文本编辑功能,包括徽标细化、拼写纠正和风格调整,同时保留周围环境。我们在图5中演示了风格参考,在图13中演示了基于视觉线索的编辑。
风格参考 给定输入图像,模型提取其艺术风格并应用它来生成多样化的新场景,同时保留原始的风格特征。
 FLOX.1 Kontext能够利用边界框等视觉线索并在保持风格的同时编辑文本
FLOX.1 Kontext能够利用边界框等视觉线索并在保持风格的同时编辑文本

Discussion
我们介绍了 FLUX.1 Kontext,这是一个流匹配模型,它将上下文图像生成和编辑结合在一个框架中。通过简单的序列拼接和训练配方,FLUX.1 Kontext实现了最先进的性能,同时解决了多轮编辑期间的字符漂移、推理速度慢和输出质量低等关键限制。我们的贡献包括处理多个处理任务的统一架构,跨迭代的卓越字符一致性,交互速度和KontextBench:具有1026个imagemprompt对的真实世界基准。我们的广泛评估表明,FLUX.1 Kontext可与专有系统相媲美,同时支持快速,多回合的创意工作流程。
局限性
FLUX.1 Kontext在其当前的实现中表现出一些局限性。过多的多圈编辑可能会引入视觉伪影,从而降低图像质量。该模型有时无法准确遵循说明,忽略了特定的提示要求。此外,蒸馏过程可能会引入影响输出保真度的视觉伪影。
编辑失败案例 顶行:身份退化的一个例子:虽然中心图像显示了良好的编辑,但保留正确的角色身份(使用稍微修改的提示)会导致严重的身份损失。中间行:场景修改而不是物体移动:模型添加牛奶泡沫而不是重新定位马克杯。底行:经过六次迭代编辑后,样本可能会表现出可见的伪影。

未来的工作
应重点关注扩展到多个图像输入、进一步扩展并减少推理延迟以解锁实时应用程序。我们方法的一个自然扩展是在视频领域进行编辑。最重要的是,减少多回合编辑期间的降级将实现无限流动的内容创建。FLUX.1 Kontext和KontextBench的发布为推动统一的图像生成和编辑提供了坚实的基础和全面的评估框架。