特点
- 高度统一:集DDL,DML,DCL于一体
- 高度非过程化:只需要提出做什么,无需声明怎么做
- 面向集合的操作:操作的对象和结果均为集合
- 两种使用方法:自主式使用(CLI,GUI),嵌入式语言
核心命令
- DDL:
CREATE DROP ALERT - DML:
SELECT INSERT UPDATE DELETE - DCL:
GRANT REVOKE
数据类型
| 数据类型 | 声明 |
|---|---|
| 数字 | NUMERIC,DECIMAL, INTERGER,SMALLINT,FLOAT,DOUBLE,REAL |
| 字符串 | CHAR, VARCHAR, TEXT |
| 二进制串 | BINARY,VARBINARY,BLOB |
| 布尔类型 | BOOLEAN |
| 日期时间 | DATE,TIME,DATETIME,TIMESTAMP |
| 时间间隔 | INTERVAL |
| XML文本 | XML |
聚集函数
聚集函数可以直接对查询结果进行统计
但是只能出现在SELECT的后面,而且只会返回一个元组
| 函数 | 返回值 |
|---|---|
| CHAR_LENGTH(string) | 字符串长度 |
| LOWER(string) | 字符串全部转换为小写 |
| UPPER(string) | 字符串全部转换为大写 |
| SUBSTRING(source, n, len) | 取长度为len的子串 |
| MAX(column) | 制定列的最大值 |
| MIN(column) | 制定列的最小值 |
| AVG(column) | 制定列的平均值 |
| SUM(column) | 制定列的总和 |
| CURRENT_DATE() | 当前日期 |
| COUNT(*) | 计算总行数 |
| COUNT(EXP) | 计算非空行数 |
与关系代数的联系
| 关系运算符 | SQL关键字 |
|---|---|
| 选择 | WHERE |
| 投影 | SELECT |
| 笛卡尔积 | FROM |
数据查询
关键字
| 类型 | 命令 |
|---|---|
| 无条件查询 | SELECT... FROM |
| 条件查询 | SELECT...FROM...WHERE |
| 列的别名 | ... AS ... |
| 带表达式的查询 | SELECT |
| 字符串匹配 | LIKE |
| 结果去重 | DISTINCT |
| 结果排序 | ORDER BY |
无条件查询
SQL语句:SELECT <字段列表> FROM <表名>
可以用*表示所有列名;
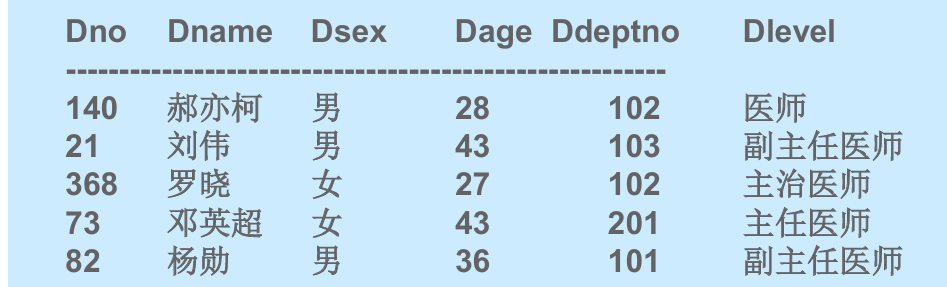
例如查询所有医生的信息:
1 | SELECT * FROM Doctor; |
结果如下:
条件查询
SQL语句:SELECT <字段列表> FROM <表名> WHERE <查询条件>
条件之间的连接可以使用以下的连接运算符:
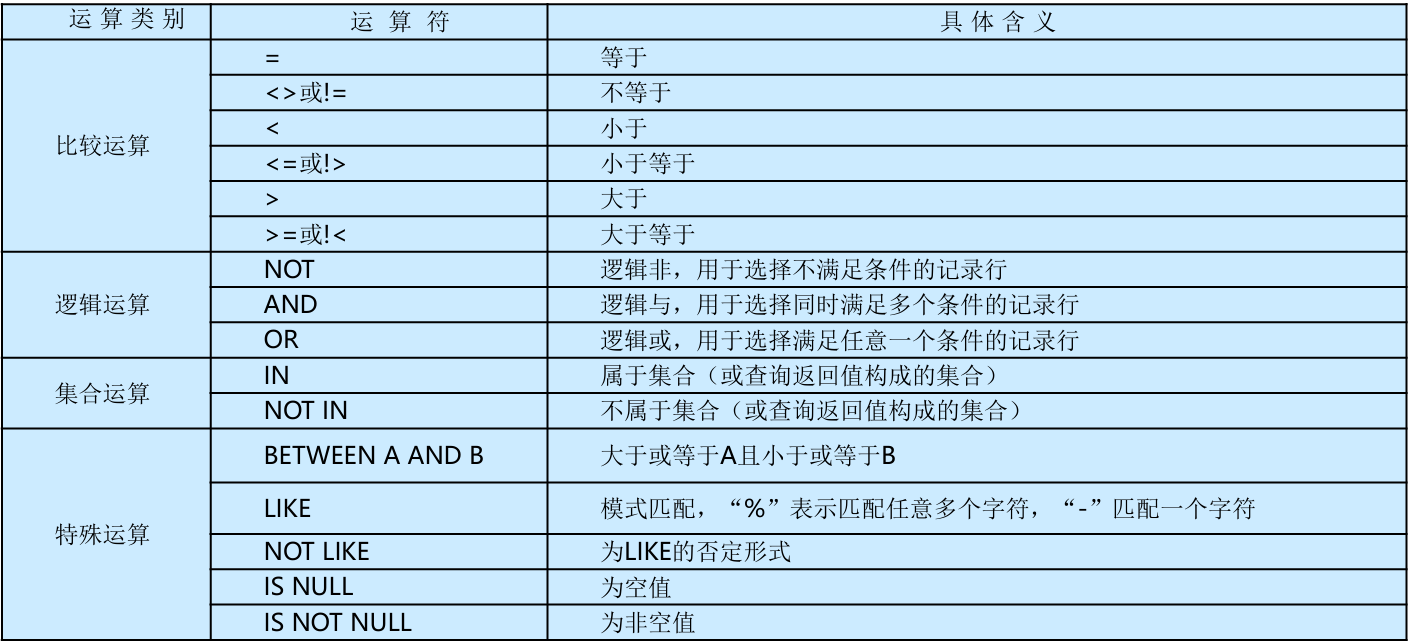
例如:查询年龄小于或等于40岁的男医生信息
1 | SELECT * FROM Doctor WHERE Dsex='男' AND Dage<=40 ; |
结果如下:

列的别名
改变查询显示列的标题,用关键字AS,跟在SELECT的属性后面;
SQL语句:SELECT <字段1> AS <别名1>,..., <字段吗> AS <别名m> FROM <表名>
例:查询医生姓名和职称并重命名
1 | SELECT Dname AS 医生姓名, Dlevel 专业职称 FROM Doctor; |
结果如下:

查询表达式
查询条件可以用表达式表示
例:在药品信息表中,查询药品单价提高15%后超过30元的药品信息
1 | SELECT Mno 编号,Mname 药品名,Mprice 单价,Mprice*1.15 调整单价 FROM medicine WHERE Mprice*1.15>=30; |
字符串匹配
字符串的模式匹配:正则表达式支持
%:表示任意长度(包括长度为0)的字符串_:表示任意单个字符
例如:查询职称为副某的医生信息
1 | SELECT * From Doctor Where Dlevel Like '副%'; |
结果去重
使用DISTINCT合并查询结果的重复记录
例如:查询部门编号
1 | SELECT DISTINCT Ddeptno FROM Doctor; |
结果排序
使用ORDER BY
- 系统缺省为升序排序
ASC - 也可以设定为降序
DESC
例如:按部门编号升序而按年龄降序查询医生信息
1 | SELECT * From Doctor ORDER BY Ddeptno ASC ,Dage DESC ; |
统计查询
统计查询是通过聚集函数实现的;它可以对查询结果直接进行统计;
- 聚集函数一般忽略空值;
- 选项
DISTINCT表示只计算不同的记录值,不计入重复值和空行; - 一次聚集函数返回一条记录
分组查询:使用GROUP BY,对所查询的表按字段进行分组,值相同的在一组,和聚集函数一起使用,聚集函数对每一组产生一个统计结果
分组筛选:使用HAVING子句,选出复合条件的统计分组,放在GROUPBY子句后
例如:
查询申请了计算机专业总申请数量
查询各个专业总申请数量;
计算机专业申请者数量大于等于2的高校;
1 | SELECT COUNT(*) FROM Apply WHERE Major='计算机'; |
连接查询
连接满足查询条件或结果来自多个表; 连接同名之短时需要消除歧义; 连接条件的不同特点:等值连接,非等值连接,自然连接,自连接
内连接
找出符合条件的共有记录,
FROM R1, R2 WHERE R1.A1 <比较运算符> R2.A2FROM R1 INNER JOIN R2 ON + R1.A1 <比较运算> R2.A2FROM R1 INNER JOIN R2 USING(A1)
等值连接
例如: 在医生基本信息表中,需要查询患者的每个处方用药信息;
1 | SELECT RecipeDetail.* Medicine.* FROM RecipeDetail, Medicine WHERE RecipeDetail.Mno=Medicine.Mno; |
自然连接
要求连接列的列名相同,并且查询结果列不重复 NATURE JOIN 例如:在医院信息数据库中,需要查询开出处方的医生信息。
1 | SELECT Rno,Pno,Dno,Dname,Dsex,Dage,Ddeptno,Dlevel |
自连接
支持表自身的连接,即同一张表的两个副本之间的连接 例如:在医院部门表中,需要医院的各部门名称和上级部门名称
1 | SELECT First.DeptName 部门名称,Second.DeptName 上级部门 |
外连接
左外连接:LEFT OUTER JOIN
右外连接:RIGHT OUTER JOIN
全外连接:FULL OUTER JOIN
不一定所有数据库支持外连接;
嵌套查询
在一个查询语句中包含另一个完整的查询语句; 外层的查询:父查询 内层的查询:子查询 子查询的结果作为主查询条件的一部分;
- 不相关子查询:子查询条件不依赖于主查询,独立执行,顺序从内至外;
- 相关子查询:子查询依赖于主查询,子查询需要引用主查询的表 例如:
1 | SELECT sID,sName,GPA |
子查询结果是一个关系,可以利用集合运算符
IN/NOT IN: 测试一个元素是否属于一个集合EXISTS/NOT EXISTS:测试一个集合是否为空- 关键字在父查询的
FROM子后
1 | SELECT sName FROM Student |
谓词
- 与集合所有元素比较
ALL例如GPA最高的学生姓名SELECT sName FROM Student WHERE GPD >= ALL (SELECT GPA FROM Student) - 与集合中任意一个元素比较
例如GPA最高的学生姓名
SELECT sName FROM WHERE NOT GPA < ANY (SELECT GPA FROM Student)
应该优先选择子查询而不是连接查询
- 查询多次带来的IO开销不可忽略
- 连接查询在内部有查找优化(索引+二分),性能并不是线性相乘
数据更新
插入操作
引入关键字:INSERT INTO … VALUES
格式如下
- 表名:指要插入数据的目标表
- 列名:指定表的目标列,参数省略时默认全部列
- 值表:具体要插入的值
1 | INSERT INTO <表名> [(<列名>)] VALUES (<值表>) |
增加操作
格式为
select子句中选择的列应该和列名保持对应- 类型和长度兼容,列名可以不同
1 | INSERT INTO <表名> [(<列名>)] <select子句> |
修改操作
引入关键字UPDATE
格式为
1 | UPDATE <表名> |
数据删除
引入关键字DELETE
格式为
1 | DELETE FROM <表名> WHERE <条件> |