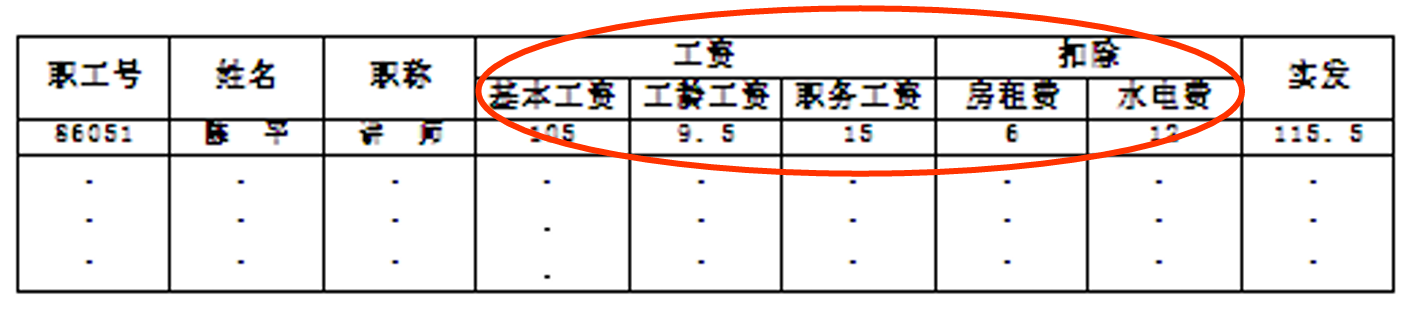
数学表示
关系模式的五元组表示:
- :关系名
- :组成该关系的属性名集合
- :属性组U中属性所来自的域
- :属性向域的映象集合
- :属性间数据的依赖关系集
对于一个简化的关系模式三元组表示:
- 数据依赖是现实世界属性相互联系的抽象
- 数据依赖是数据内在的性质
- 数据依赖是寓意的体现 规范化解决的问题是如何构造合适的关系模式
设计好的模式:大模式的分解,信息完整
模式的分解:自动化,模式设计包含所有信息,按照一定规则分解的小模式没有数据冗余和更新异常
数据依赖
- 函数依赖FD:一个关系表中属性之间的联系
- 多值依赖MVD:关系中属性之间在语义上的关联特性
函数依赖
对于关系模式,,设是关系中的任意两个元组;
称函数依赖于,称为决定因子,称为依赖因子,若,则;
- 对于,这种情况视为平凡函数依赖
- 由于不反映新的寓意,所以函数依赖一般指非平凡的;
完全依赖/部分依赖
对于是关系的不同属性集,满足;
若,称完全函数依赖于,否则称为部分依赖
传递依赖
对于是关系的三个不同的属性集
若,有, 称传递依赖于
- 某一个属性列唯一,那么这个属性可以决定其他属性
- 这个属性的任意超集也可以决定其他属性
逻辑蕴含
对于关系上的依赖集
若在上也成立,称逻辑蕴含,记为
也就是说,一个函数依赖可以由其他函数推出,那么这个函数依赖被视为多余的;
对于函数依赖的闭包,定义为
- 这个集合定义了由给定函数依赖集能够推导出所有的函数依赖
- 根据一直的函数依赖集,推导出其他函数依赖的规则称为推理规则
- 由已知函数依赖集推导闭包是NPC问题;
Armstrong公理
闭包中的函数依赖可以通过三个关系找出,这样的推导是正确且完备的,不过从找到对应的闭包是一个NPC问题;
- 自反性:
- 增广性:
- 传递性:
- 合并性:
- 伪传递性:
- 分解性:
- 复合性:
- 通用一致性:
属性集闭包
定义以下的属性集闭包:
属性集的闭包是P问题;能使用Armstrong规则推导出的充分必要条件为;
属性集闭包算法:
1 | X_clo := X |
最小依赖集
函数依赖集逻辑等价记作;
是的两个函数依赖集,若,称是等价的函数依赖集;
最小依赖集定义如下:
- ;
- 每个函数依赖的右边是单属性;
- 没有冗余的函数依赖;
- 每个函数依赖左边没有冗余的属性
最小依赖集算法:
- 计算等价的,要求的每个依赖集右边为单属性;
- 消除中每个函数依赖左边的冗余属性
- 消除中的冗余的函数依赖
候选码
若为中的属性或者属性结合,若,则为的候选码;
若候选码多于一个,可选定一个当作主码(primary key)
- 单个属性是码,称为单码
- 整个属性组是码,称为全码
模式分解
函数依赖可以引起的数据冗余和更新异常等问题,需要对关系模式进行分解
关系模式的分解就是用两个或两个以上关系来替换,分解后的关系模式的属性集都是中属性的子集,其并集与的属性集相同
具体来说,对属性集,关系模式,若用一组关系模式的集合来取代,则称此关系模式的的一个分解,记作
关系模式分解的两个特性实际上涉及两个数据库模式的等价问题
- 数据等价是指两个数据库实例应表示同样的信息内容,如果是无损分解,那么对关系反复的投影和连接都不会丢失信息;
- 依赖等价是指两个数据库模式应有相同的依赖集闭包。在依赖集闭包相等 情况下,数据的语义是不会出错的
保持依赖
设是的一个分解;是的一个FD集;
如果
称分解保持函数依赖集
无损分解
对于关系模式,其一个函数依赖集为,其一个模式分解为,
若对于中满足的每一个关系,均有
则称分解是相对于依赖集的一个无损连接分解,否则则是有损分解;
利用Chase算法将关系模式一分为二,判断是否为无损分解;
设是关系模式的一个分解,则是无损分解的充分必要条件为以下关系满足其一即可
模式分解能消除数据冗余和操作异常现象, 分解以后,检索需要作笛卡尔集或连接操作,带来时间开销,为了消除冗余和异常,对模式的分解是值得的;
范式
范式是关系的状态,也是衡量关系模式的好坏的标准,一个规范化的方式有最小的数据冗余
除了与援助进行连接的外键之外,数据库实例中的其他属性值不能被复制
1NF
在每个关系模式每个属性值都是不可再分的原子值;1NF是关系模式应具有的最起码条件;
换言之,1NF要求不存在表中之表;
2NF
在1NF的基础上,消除了部分依赖导致的冗余和操作异常,2NF是通往更高范式的中间步骤,它消除了1NF存在的部分问题,但仍可能出现冗余和异常;
如果关系模式且每个非主属性完全依赖于候选码,称满足2NF;
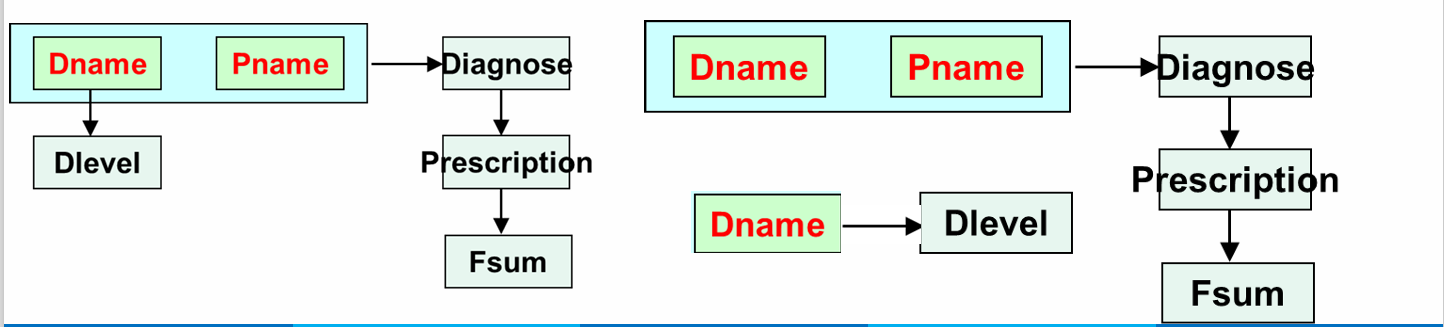
以下简单情况必定满足2NF
- R的码是单码
- R的码是全码
- R是二元关系
2NF分解算法:
-
对于关系模式,主键为,上存在函数依赖,其中是非主属性, 则是部分依赖,进行分解
- ,主键为
- ,主键为,外键为
-
若仍然不是2NF,重复上述分解过程
3NF
若关系模式,而且每个非主属性都不传递依赖于的候选码,称属于3NF;
定理:若是3NF,必有是2NF 证明:对于关系模式,主键为,若存在部分依赖,意味着R上存在函数依赖,其中是非主属性,,可以看成,这样特殊的传递依赖;
以下的简单情形必定满足3NF;
- 关系模式是全码;
- 所有二元关系;
3NF分解算法:
-
对关系模式,主键为,上存在FD:,其中非属性,不是候选键, 说明是传递依赖,进行如下分解
-
,主键为
-
,主键为,外键为
-
-
若不是3NF,继续进行如上分解
分解的原则应该从传递依赖链的尾部开始;
BCNF
BCNF,也称修正3NF,若关系模式R是1NF,而且每个属性都不传递依赖于R的候选码,那么称R是BCNF;
- 非主属性对每一个码都是完全函数依赖;
- 非主属性对不包含它的码也是完全函数依赖;
- 没有任何属性完全依赖于非码的任何一组属性;
关系为单码,并且已经是3NF,那么关系一定是BCNF;
BCNF分解算法
- 对于关系模式R,R上成立的函数依赖集F,找到最小依赖集;
- 将最小依赖集中左部相同的FD用合并性合并,
- 对最小依赖集中的每个FD 构成模式
- 对于生成的模式集中,若每个模式不包含R的候选码,此时将候选码作为一个模式放入模式集中
不过这样的分解可能是有损的,违背了我们分解的初衷;
反范式
提高查询效率,采用空间换时间的实现思路;
- 存在频繁查询时,可以容忍适当的冗余设计,目的是减少多表关联 查询,提高效率
- 有些信息频繁变动,需要保存历史信息反范式化一定要适度,并且在原本已满足三范式的基础上再做调整的