Introduction
架构
CNN的训练样本是带有标签的。在很多实际应用中, 训练样本是没有标签的。应用误差反向传播算法来训练网络会遇到一些困难。
自编码器(autoencoder)采用让输入和输出相等的idea, 隐含层用于记录数据特征,这是典型的表示学习(representation learning)/特征学习(feature learning)办法,由Hinton等人提出;

autoencder是一种尽可能重构输入信号的神经网络,必须捕捉可以代表输入数据的最重要的内在因素
- 给定输入和输出相同的一个神经网络
- 训练网络获得隐藏层的权重,每一层就是一种表示/特征(representation);
训练
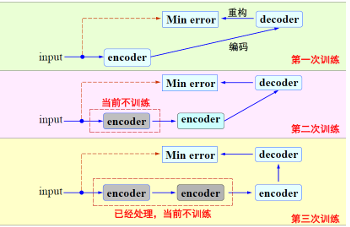
具体来说,在第一次编解码训练中/网络表达中
-
为input序列增加一个encoder,得到输入的一个representaion,记作
-
继续增加一个decoder,输出最终的使用信号重构的方式评估这个representaion的质量
-
目标是最小化输入输出的差异,训练隐含层的权重矩阵;
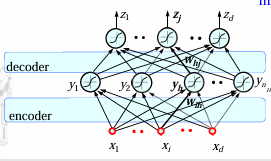
Autoencoder的训练过程是逐层静态进行的,通过对encoder的stack,不断将前一层输出的code作为后一层输入的信号;
在完成Autoencoder 的学习任务之后,在实际应用中,在解码阶段学习得到的权重将不进行考虑。因此,编码阶段获得的网络系统其实质是一种特征学习。层级越高,结构特征越大越明显。
- 对于分类任务,可以事先用Autoencoder 对数据进行学习。然后以学习得 到的权值作为始初权重,采用带有标签的数据对网络进行再次学习,即fine tuning技术。
- 为了实现分类任务,需要在编码阶段的最后一层加上一个分类器,比如一个 多层感知器(MLP)
扩展
在早期Hinton的工作中,采用RBM 来 预训练网络,同时采用对称的网络结构,即解码器中的权重矩阵与编码器中的权重矩 阵呈转置关系。一个原因是当时训练数据少,且计算能力有限;
正则编码器(regularized AE): 可以使得提取的特征符合某种性质,应用惩罚大权重的L2正则化
稀疏自编码器(Spare AE)基于高维稀疏表示的假设,提取稀疏的特征表示,采用神经元平均激活度为度量
采用如下的稀疏约束限制神经元平均激活度在一个很小的度
去噪自编码器(denoising AE)基于对噪声化的原始数据根据编码和解码,能还原真正原始数据的鲁棒特征,通过提取鲁棒的特征表示,完成去噪工作;
它假定污染是如下过程
采用如下的编解码过程
总的来说,这些自编码器的工作,它们的目的都是数据将为,都具有编码器和解码器的结构,具有窄的bottleneck,通过对输入信号的重建,将输入降维成一种表征;因此,autoencoder不是一种生成模型。