语义
定义:语言的单词符号和语法单位的作用和意义的规则组合;
一般用自然语言描述语义,使用抽象机(grammar abstract machine)的行为来描述语言语法单位的作用和意义,GAM主要用于实现惰性求值和图归约;
GAM
组件
- 存储区:分为代码段和数据段;
- 代码段存放执行的指令代码的内容不允许修改;
- 数据段存放必要的信息和程序中的数据;
- 控制器
- 处理器
- 指令指针
ip:指向代码段单元的地址,表示当前指令;自增操作:ip = ip + 4表示指针指向下一条指令,如果每条指令占4个字节的话;
工作方式
GAM一旦启动,由专门的装入程序将待运行的程序装入代码存储区,并设置ip指向第一条指令,并执行如下操作
- 执行
ip指向的当前指令; - 若
ip指向STOP指令,则终止执行; - 若指令未修改
ip,则ip自增,指向下一条指令; - 若修改了
ip,则跳转到修改后ip指向的指令;
语义分析
语义分析(semantic analyzer)使用语法树和符号表检查源程序是否和语言定义的语义一致,同时收集类型信息;语义定义了程序的含义;
主要工作分为
- 静态语义检查:类型检查(type checking),控制流检查,一致性检查等
- 语义处理:自动类型转换(coercion),说明语句登记信息,执行语句生成中间代码等
静态检查一般由编译器前端完成,抛出特定类型错误;
- 语法检查:部分包括在语法分析的文法中的语法要求;
- 类型检查:部分语言实现自动类型转换(coercion);
- 左值和右值:考虑运算符的结合问题;
符号表
形式
符号表中每个名字对应一个表项,包括名字域和信息域;
- 信息域设置若干子域和标志位,包括属性,类型,长度,相对地址,形参标志,说明标志,赋值标志等;
- 每个表项的组成和长度可能是不同的,需要采用简洁表技术;
符号表
符号表除了记录名字本身而外,还记录了与名字关联的各种属性信息。
每个名字对应一个表项,一个表项包括名字域和信息域。信息域通常设若干子域及标志位,其内容可以是和名字有关的任何信息,比如类型,种属,长度,相对地址,形参标志,说明标志,赋值标志等。
结构
实现结构可以采取线性表,或者Hash表实现;
语义分析
语义分析(semantic analyzer)使用语法树和符号表检查源程序是否和语言定义的语义一致,同时收集类型信息;
- 类型检查(type checking)
- 自动类型转换(coercion)
语义定义了程序的含义;
语法制导翻译
定义
上下文无关文法不仅可以描述一个语言的语法,还可以制导程序的翻译过程,这种技术称为 语法制导翻译(syntax-directed translation);
一个属性(attribute)是指某个与程序构造相关的量;
比如表达式的数据类型,生成代码的指令数;在语法分析树上体现为结点上标记了相应的属性值,这样的树也称作注释分析树;
对于一个语法制导定义(syntax-directed definition)实现了
- 将每个文法符号和一个属性集合相关联;
- 把产生式和一组语义规则(semantic rule)相关联;
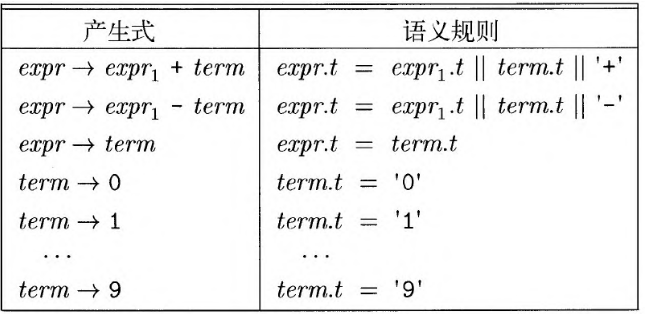
换而言之,为每个产生式配上一个语义子程序 ,在语法分析过程中,使用一个产生式进行匹配或归约后; 就调用相应的语义子程序,进行语义分析。
对于一个语法制导的翻译方案(translation scheme),定义为将程序片段附加到一个文法的各个产生式的表示法;
- 在语法分析使用一个产生式时,相应的程序片段将被执行;
- 顺序组合这些方案,执行可以得到源程序的翻译结果;
- 根据产生式,生成了中间代码,语法分析完成时,也就获得了完整的与源代码等价的中间代码。
对注释语法树来说
- 一次深度优先遍历,会自顶向下地计算子结点属性后,得出根节点的属性值;
- 可采用前序遍历和后序遍历的方式,根据相关动作执行时间来定义结点次序
语法制导翻译方案是一种在文法产生式中附加程序片段来描述翻译结果的表示方法;
- 语义动作:被嵌入到产生式体中的程序片段称为语义动作;
- 生成翻译方案的语法分析树时,需要为每个语义动作构造一个额外的,产生式头部的子节点;
- 在一次后续遍历中,先所有执行语义动作,然后访问没有语义动作的子节点;
比如在LR分析过程中,使用一个产生式进行句柄的规约后,调用该产生式的响应的语义子程序,完成语义分析;
- 包括语义检查和语义处理;
- 核心是生成中间代码;
- 在分析过程中每一次规约时,必须保存语义值;
考虑一个翻译方案
1 | expr -> expr + term {print('+')} |
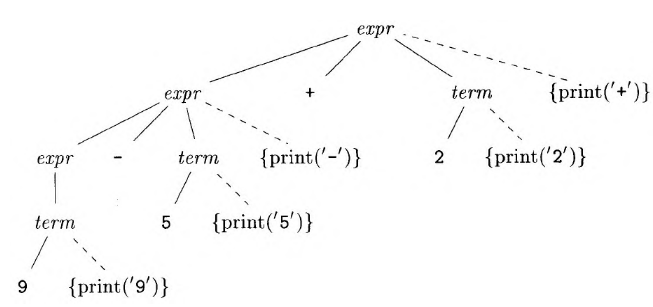
通过拓展文法得到一个翻译器,我们可以拓展一个预测分析器来获得一个语法制导翻译器;
消除左递归
将上述翻译方案的左递归消除后
1 | expr -> term rest |
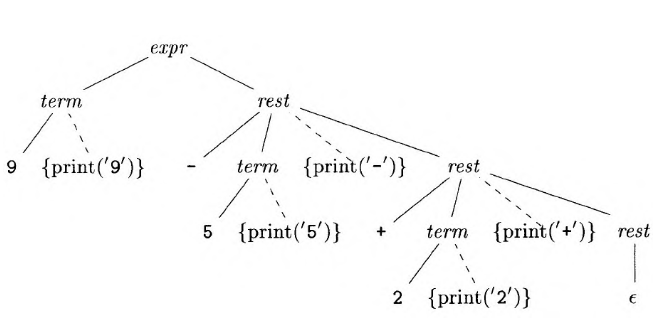
消除尾递归
若过程体执行的最后一条语句时对该过程的递归调用,则称这个调用是尾递归的(tail recursive);
对于一个没有参数的尾递归调用可以改写为迭代;
调用符号表
符号表的作用是将信息从声明的地方传递给实际使用的地方;
分析标识符的声明时,定义一个语义动作将有关从符号表中取出这个给标识符的信息;
中间表示形式 & 虚拟机
后缀表示
对于我们熟悉的一个中缀表达式,其后缀表示(postfix notation)/逆波兰表示(reverse Polish notation)定义如下,记作
-
若是一个变量或常量,则;
-
若是形如的表达式,则
-
若是形如的表达式,则
如上性质表明后缀表达是一种无括号的数学表达式表示法,其核心为运算操作符后置,无需括号也可明确运算顺序;
这样的数据结构可以对应一类栈式自动机;
抽象语法树(abstract syntax tree)
- 内部节点代表程序构造;
- 每个内部结点和一个运算符关联;没有对应于单产生式,也没有空产生式;
树型结构包括语法分析树和抽象语法树;实际上,抽象语法树的结构不会被存储在特定数据结构中,在编译过程中,它被假装构造出来,伴随着三地址代码的生成;
当语法树生帮助生成的三地址代码构造成功后就会释放那部分树;
三地址代码 & 四元式
三地址代码时最重要的线性表示形式;通常包括一个操作码op,和三个操作数x,y,z,使用相对地址表示;
- 二元运算类语句的一般形式为
x:= y op z或者(op,x,y,z); 对于运算类操作,y,z指出运算的两个对象,x用来存放运算的结果,op为二元算术或逻辑运算符; - 一元运算类赋值语句
x:=op z,op为一元运算符,如一元负uminus,逻辑否定not,类型转换itr等 - 复制类赋值语句
x:=y - 无条件转移语句
goto L,流程转移到序号为L的语句 - 条件转移语句
if x rop y goto L或if a goto L,rop为关系运算符 <、<=、==、>、>=、<> 若x和y满足关系rop,或a为true时,就转向执行序号为L的语句,否则顺序执行下一语句。
四元式顺序和表达式计值顺序一致;四元式之间通过临时变量实现关联。使用ip表示四元式编号(序号,从1开始)
特别的,我们约定(itr, x, _, t)的含义是将符号表入口x的整数变量转换为实数类型t;(rti, x, _, t)的含义是将符号表入口x的实数变量转换为整数类型t;
翻译
语义变量和语义过程
| 语义 | 类别 | 作用 |
|---|---|---|
i.NAME |
语义变量 | 表示变量的标识符字符串 |
E.PLACE |
语义变量 | 表示变量在符号表的地址或整数编码 |
newtemp() |
语义过程 | 创建临时变量,返回整数编码 |
entry(i) |
语义过程 | 为变量i查符号表 |
emit(res, s1, op, s2) |
语义过程 | 产生三地址语句res:=s1 op s2,同时ip自增,这里s1,s2都是指符号表某个地址 |
error() |
语义过程 | 报语义错误 |
enter(name, type, offset) |
语义过程 | 将变量的名字,类型和相对地址写入符号表 |
backpatch(r, ip) |
语义过程 | 把r为链首的三地址语句转移地址填为ip的当前值 |
merge(p1,p2) |
语义过程 | 将p1,p2为链首的两条链拼接起来 |
翻译说明语句
对于单个变量的说明,文法表示为
1 | S → MD |
则产生的说明语句子程序/方案为
1 | (1) M → ε {OFFSET = 0;} |
翻译赋值语句
对于赋值简单变量,文法表示为
1 | S → A |
对于已经声明的变量,应该先查找变量名表;
对于赋值语句的翻译,需要进行类型检查和自动类型转换,翻译的顺序按照语法制导来,产生的说明语句子程序/方案为
1 | S → A {S.CHAIN = 0;} |
其中{check}表示类型检查的步骤,具体来说是个形如以下(op为+)的过程;
1 | E.place :=newtemp( ); |
布尔表达式的翻译
我们考虑位于控制语句中的布尔表达式,在读到转移语句的时候,具体转移的目的地尚不可知,暂记为0;
对于布尔变量和布尔表达式对应的语义子程序都有4步,对真假分别判断;
1 | B → b{ B.T = ip; emit(if b goto 0); B.F = ip;emit(if b goto 0);} |
无条件转移语句的翻译
通常goto语句的产生式如下,也可能具有如下的向前转移和向后转移形式;
1 | label → i: |
条件跳转语句的翻译
条件跳转语句的复杂之处在于嵌套;我们考虑如下产生式
1 | S → MS1 |
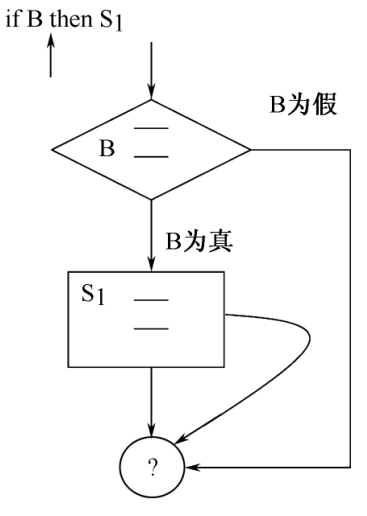
整个语句翻译完成后,仍然不确定B.F,只能将它作为S.CHAIN暂时保留下来,那么对应的语义子程序为
1 | (1) M → if B then {backpatch(B.T, ip); M.CHAIN = B.F} |
对于更复杂的嵌套情况
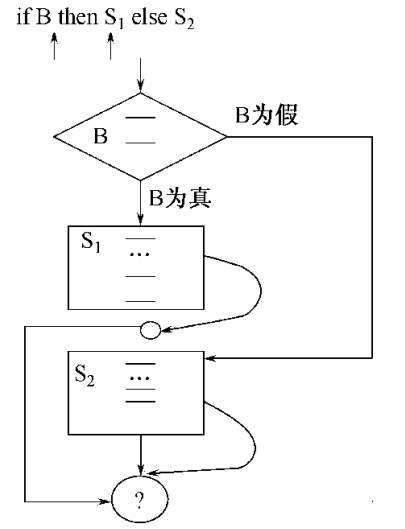
1 | S → NS2 |
我们需要更多的合并和跳转的操作
1 | (1) M → if B then {backpatch(B.T, ip); M.CHAIN = B.F} |
while语句的翻译
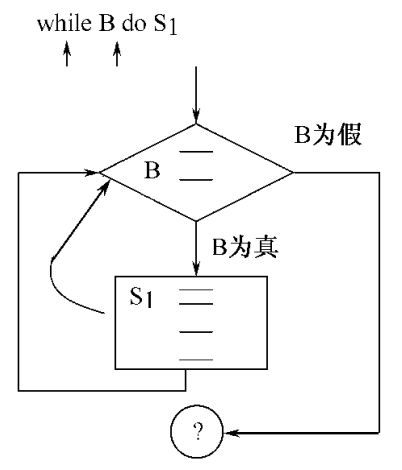
根据文法建立子程序
1 | (1) W → while {W.CODE = ip;} // 这里的CODE只是个标签 |
for语句的翻译
for语句的目标结构如下图所示,一个典型的文法结构为S→ for i:=E1 step E2 until E3 do S1
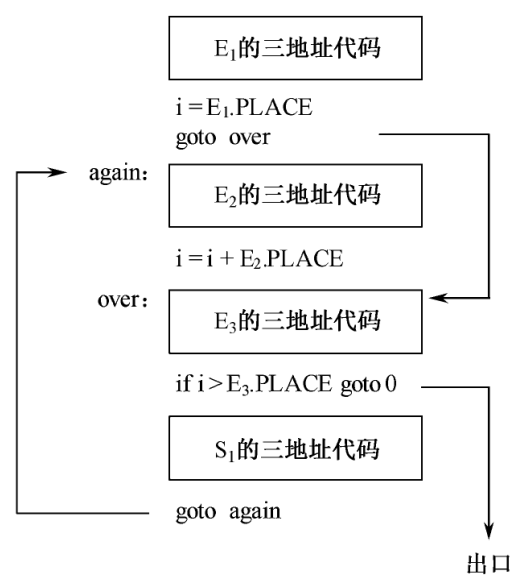
相当于实现语句
1 | i:=E1; |
1 | (1) F1 → for i:=1 { |