词法分析
概述
词法分析(Lexical Analysis / Scanning)是编译过程的第一个阶段。
它接收源程序的字符流 (character stream)作为输入,并将其组织成一系列有意义的词素 (lexeme)。随后,对于每个词素,词法分析器会生成一个记号 (token) 作为输出,传递给语法分析器。
这个记号就是一个词法单元,就是一个带有附加信息的终结符号;
核心任务 🎯
扫描源程序的字符串,按照词法规则,识别出单词符号作为输出;
- 读取输入: 逐个读取源程序中的字符。
- 识别词素: 将字符组合成词素(Lexeme) 📜,源程序中与某个记号的模式匹配的实际字符序列。例如,在语句
count = count + 5;中,count,=,+,5,;都是词素。词素内部的空格通常被忽略(除非它们是字符串字面量的一部分或用于分隔词素)。 - 生成记号: 为每个识别出的词素生成一个记号;
- 记号 (Token) 🪙: 一个抽象的符号,代表一类词法单元。通常表示为一个二元组:
(token-name, attribute-value)。token-name: 词法单元的类别,如identifier,keyword,operator,number,punctuation。attribute-value(可选): 指向符号表中关于这个词素的条目。对于标识符,它可能是标识符的字符串;对于数字,它可能是数值。对于关键字或操作符,此字段可能为空或不使用。
- 模式(Pattern) 🧩: 描述一个记号的词素可能具有的形式的规则。通常用正则表达式来定义。例如,一个标识符的模式可能是"一个字母后跟零个或多个字母、数字或下划线"。
- 记号 (Token) 🪙: 一个抽象的符号,代表一类词法单元。通常表示为一个二元组:
举例说明 🌰
考虑以下C语言语句:
result = initial_value + rate * 60;
词法分析器会将其转换为如下的记号流 (token stream):
- 词素
result➡️ 记号<id, "result"> - 词素
=➡️ 记号<assign_op> - 词素
initial_value➡️ 记号<id, "initial_value"> - 词素
+➡️ 记号<add_op> - 词素
rate➡️ 记号<id, "rate"> - 词素
*➡️ 记号<mul_op> - 词素
60➡️ 记号<number, 60> - 词素
;➡️ 记号<semicolon>
其他职责 🛠️
- 去除空白和注释: 词法分析器通常会跳过源程序中的空格、制表符、换行符和注释,因为它们通常不影响程序的语义(除非它们用于分隔词素)。
- 错误报告 ⚠️: 报告词法错误,例如遇到不符合任何模式的字符(如非法符号)。
- 与符号表交互 📇: 将标识符等词素的属性信息存入符号表。
在编译过程中,词法分析可以仅仅执行一次;
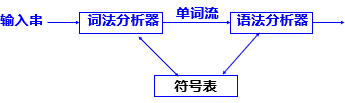
也可以执行多次;
数据结构🧱
1 | enum kind {IF, LPAREN, ID, INTLIT, …}; |
在多数程序语言设计中,单词种类一般有如下种类:
- 标识符:标识符、常量由用户定义/使用, 语言未加限制,只规定了相应的词法规则;
- 关键字,运算符,分界符:数目是确定的,每个单词与其类别码一一对应,因此采取一字一码,即第二元可以空缺;
- 常量:整型、实型、字符型、布尔型等分类
词法分析器
输入 & 输出 & 流程
-
读入源字符串
-
输出二元式序列
-
包括单词符号 + 种别
-
如果有错误,则改输出错误信息
- 格式:
LINE <id>: <error info> - 一般有三种错误:非法字符,冒号不匹配,标识符长度溢出
- 格式:
-
-
进入一个阶段,需要先检查错误信息
peek技术
在决定像语法分析器返回token之前,词法分析器可能需要预先读入一些字符;
比如遇到
>后需要检查下一个是否是=,标识符是否在下一位结束等;
一个通用的预读办法是使用输入缓冲区,由于通常只需预读一个字符,所以缓冲区大小为1,即将下一个输入字符保存在一个变量peek中;
当词法单元返回一个token时,peek要么保存了该token的词素后面一个字符,要么为空白符;
我们可以使用一个指针跟踪已经被分析的输入部分,放回缓冲区通过回移指针实现;
对于大型编译器的实现,往往采用双缓冲技术;
解析常量
当输入流中出现一个数位序列时,词法分析器将它解析为一个数字常量;

解析关键字和标识符
关键字也满足标识符组成规则:开头为字母或下划线,往后为数字或下划线或字母;通常实践下,词法分析器使用一个表保存在字符串,后续通过引用操作字符串;
词法分析器在初始化应该在构建关键字表(reserve table),每一项包括保留的字符串和对应的词法单元;还有空的标识符表words;
- 当读到一个可以组成标识符的词素时,应该先检查关键字表;
- 检索到,则返回关键字表中的词法单元;
- 否则,与
words交互,查到返回位置编号,否则将它存入符号表并返回新编号;

扫描算法

基于状态转换的框架
-
当前字符:用一个变量
cha记录 -
case:当前字符的值识别不同类型单词 -
每个状态对应于一段代码:
-
分支状态:
if或case语句 -
循环状态:
while语句
-
-
进入某个接受状态时,某个单词识别结束。
- 终态:
return语句 - 错误
- 终态:
-
注意自动机状态有错误标记*
实现原理
算法需要设计如下变量和函数:
cha:最新读入的字符;顺便维护所在wei'zhitoken:已读入的字符串;getchar(): 从源程序文件读入下一个字符;getnbc(): 读入非空白字符;concat(): 把cha加入到token的末尾;isLetter(): 判断是否为字母;isDigit(): 判断是否为数字;reverse(): 对token查关键字表,查到返回关键字的编码种类,否则返回0表示不是任何单词符号;retract(): 回退字符,把刚读入的cha中的字符回退到输入字符串中,cha置空;buildList(): 对token查符号表,查到返回位置编号,否则将它存入符号表并返回新编号;dtb(): 将token的数字串转换成二进制,查常数表;查到返回位置编号,否则将它存入常数表并返回新编号;return()->(num, value): 返回编码种类 + 位置编号error(): 处理可能的词法错误;
可能存在一类词法错误,比如写错关键字,标识符带有空格,这种错误一般会推迟到语法分析抛出;
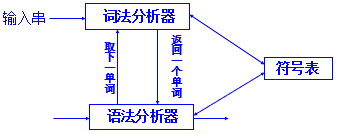
词法分析程序作为语法分析程序的一个子程序,当语法分析需要下一个新单词时,就调用该程序,从输入字符串中识别一个单词后返回。
词法分析程序另一种被调用方法,这一般是主流实践;
- 被编译程序只调用一次
- 增加一个大循环(文件是否结束)
return改为 向文件写入二元式;- 该文件保存所有的二元式,语法分析程序通过该文件获取单词;
词法错误
比如以下程序片段
1 | fi(a == b) ... |
词法分析器无法判断if是否拼写对,它会将fi识别成一个普通标识符,可能有两种场景
- 未定义标识符:如果该符号之前没有定义过,而
fi前面没有声明语句,就会直接抛出该错误; - 其他:如果已经被定义过了,则词法分析不报错,推迟到语法分析处理错误;
如果遇到所有词法单元模式均无法与剩余的输入前缀匹配,则词法分析器将陷入恐慌,无法继续处理;
一般会执行一个恐慌恢复策略:从剩余输入中不断删除字符,直到输入开头出现一个正确的词法单元为止;