语言处理器 ⚙️
概述
通常来说,一个编译器(compiler) 👨💻➡️💻 将程序设计语言翻译成被计算机执行的形式;
- 阅读宿主语言(host language),通过宿主机器(host machine),翻译成等价的目标语言。
- 需要将翻译过程的错误抛出 ⚠️。
- 如果目标语言是机器可执行的语言程序,执行目标程序,可以处理用户的输入得到输出。
解释器(interpreter) 🗣️ 逐行执行:
- 没有显式的翻译步骤,直接解释执行源程序。
- 利用用户的输入,执行源程序中的操作,得到输出。
比较来看,编译器编译后运行获得输出相对较快 🚀,但是解释器错误诊断和调试通常更好 👍。
若编译程序生成宿主机执行的机器代码,称为自驻留的编译程序;若编译程序是用源语言编写的,则为自编译的编译程序;若编译程序生成的不是宿主机执行的机器代码,称为交叉编译;
这里详细介绍交叉编译:
在一个Host平台上生成另一个Target平台可执行代码的编译过程,常用于嵌入式开发、跨平台应用构建等场景,通常出于以下考虑:
- 资源限制:目标设备(如物联网设备)无法运行完整编译器
- 效率需求:在高性能Host平台编译可加速构建过程
- 跨平台支持:为Windows/MacOS/Linux生成多平台二进制文件
在C和C++的实践中,通常使用CMake等工具链实现交叉编译,而在一些语言(比如Golang)的编译器天然支持交叉编译选项;
结构
一个预处理器(preprocessor) 🧩:
-
负责将独立文件中的源程序多个模块组合在一起;
-
根据编译选项,选择条件编译;
-
删除注释,合并空白符;
大部分语言允许此法单元之间出现任意数量的空白,注释也当空白处理;
-
将宏 (macro) 的缩写转化成源语言语句。
比如C语言中遇到
#include <iostream>负责将iostream库中的内容组合到目标程序;遇到
#define PI 3.14159,则会将文件中的PI替换成3.14159。
汇编器(assembler) 🛠️:
- 处理编译器产生的汇编语言程序。
- 生成可重定位的机器代码 (object code)。
- 大型程序一般多个文件分部分编译,这些可重定位的机器代码和库文件需要连接到一起。
链接器(linker) 🔗:
- 一个文件的代码可能引用另一个文件定义的符号 (如函数或变量)。
- 链接器解决这些外部内存地址的问题,将多个目标文件和库文件合并成一个可执行文件。
加载器(loader) 🚀:
- 将可执行文件从磁盘加载到内存中准备执行。
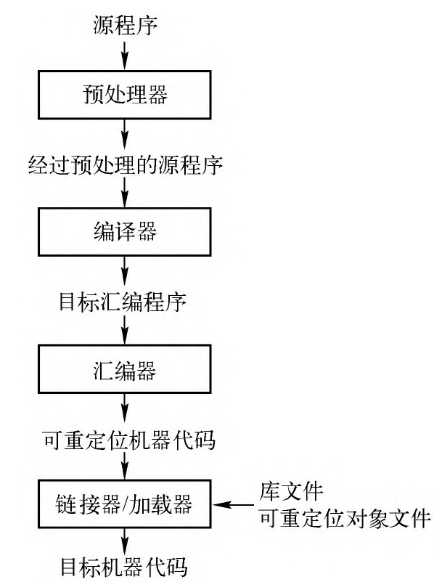
流程
编译器将源程序映射为语义等价的目标程序,由两部分构成:
- 前端/分析(analysis):将源程序分解,加上先验的语法结构
- 创建源程序的中间表示;
- 创建符号表(symbol table);
- 报语法错误;
- 后端/综合(synthesis): 输入中间表示和符号表,输出期待的目标程序;
.png)
具体分工如下:
- 词法分析 (Lexical Analysis) 🧐: 读入源程序字符流,将其组织成有意义的词素 (lexeme) 序列,然后为每个词素生成并输出一个记号 (token) 流。例如,将
count = count + 5;转换为id(count),assign_op,id(count),add_op,number(5),semicolon。 - 语法分析 (Syntax Analysis) 🌳: 根据词法分析器产生的记号流,使用语言的语法规则 (grammar) 来构造程序的层次结构,通常表示为一棵语法树 (syntax tree) 或分析树 (parse tree)。这一步检查程序的结构是否正确。(参考 [[第2章-语法分析#语法树|语法树]])
- 语义分析 (Semantic Analysis) 🤔: 使用语法树和符号表中的信息来检查源程序是否与其语言定义的语义一致。主要任务包括类型检查 (type checking),确保操作符和操作数类型兼容,以及其他静态检查(如变量声明、函数参数匹配等)。同时收集类型信息供后续阶段使用。
- 中间代码生成 (Intermediate Code Generation) ⚙️: 在将源程序翻译成目标代码之前,许多编译器会先生成一个明确的、机器无关的中间表示 (Intermediate Representation, IR)。常见形式有三地址码 (three-address code),它易于生成和优化。
- 代码优化 (Code Optimization) ✨: (可选阶段) 尝试改进中间代码,以产生性能更好(运行更快、占用内存更少、能耗更低等)的目标代码。优化可以在不同层面进行,如局部优化、全局优化、循环优化等。
- 代码生成 (Code Generation) 💻: 将(优化后的)中间代码映射到目标机器的指令集。此阶段涉及指令选择 (instruction selection)、寄存器分配 (register allocation) 和指令调度 (instruction scheduling)。最终为每个变量选择内存地址或寄存器。
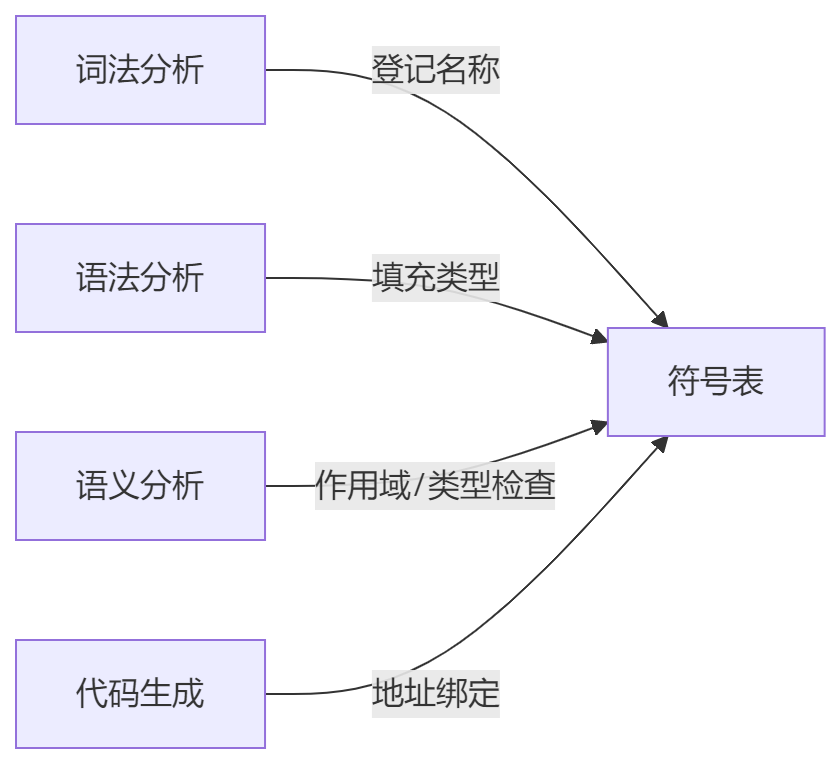
符号表
符号表(symbol table)是供编译器用于保存有关源程序构造的各种信息的数据结构;
声明周期
符号表在分析阶段逐步收集,用于生成目标代码;
- 每项包含一个与标识符有关的信息,如词素,类型,存储位置;
- 需要支持同一个标识符的多重声明;
- 每个带有声明的程序块都有自己的符号表,因此需要对每个作用域建立单独的符号表;
数据结构
一个典型的符号表链如下:
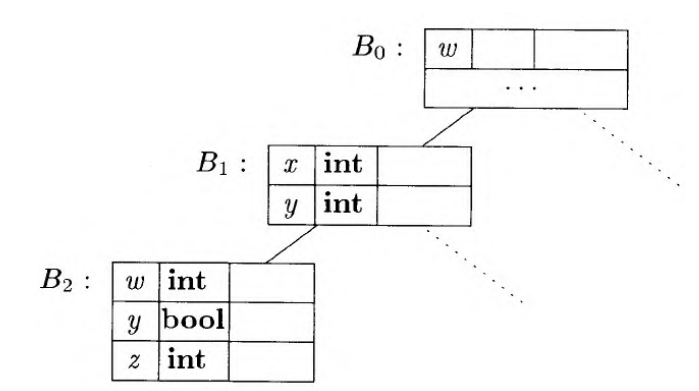
一个典型的符号表Env的实现

C语言编译器示例 🔬
现在我们拥有一个main.c文件,内容如下:
1 |
|
预处理
执行命令gcc -E -o hello.i hello.c,得到文件hello.i,内容如下,这样我们完成了文件通过了预处理器,完成了预处理的步骤,这一步不处理语法错误,执行预处理指令,可以看到MYMAX替换成20了;
1 | # 0 "main.c" |
编译
执行命令gcc -S -o main.s main.i,得到文件main.s,内容如下,这样的汇编语言程序结果和硬件架构相关;
1 | .file "main.c" |
汇编
执行命令gcc -c -o main.o main.s,得到main.o文件,编辑器已经不可查看了,而且系统也不能执行该文件,内容为机器码;
不可执行的原因是还未进行重定位操作,数据的地址没有确定;
链接
执行命令gcc -o main main.o,得到最终的可执行文件main;