Transformer介绍
Seq2Seq任务
对于一类Seq2Seq任务,输入和输出都是序列的任务,输出的长度不确定时采用的模型,常见于机器翻译中;
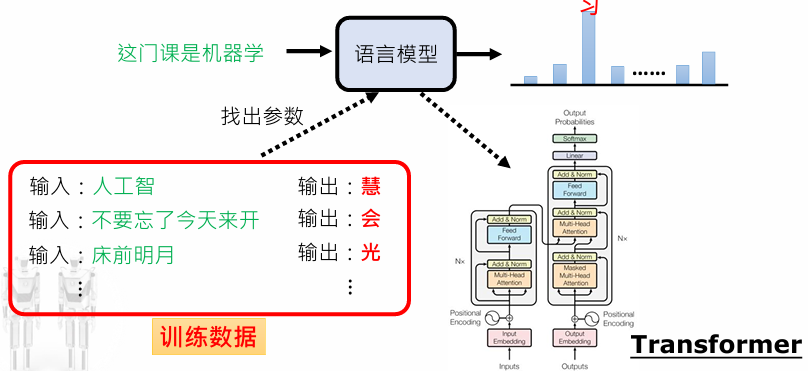
针对一类序列模型和 transduction-problem(语言处理,机器翻译等),Google提出一种简单的网络架构Transformer
- 只基于注意力机制(attention mechanisms) 构建输入输出的全局依赖
- 完全舍弃RNN和CNN的transduction model
- 允许并行化提高计算效率,减少串行计算(现有模型运算次数和输入输出所在位置距离有关),引入多头注意力机制(Multi-Head Attention)
Tokenization
观察到长句子总是由单词组成的,我们把语句中有意义的词块组成为token,这些token一般需要训练形成token表,最终设计的效果是意思相近的token具有接近的embedding;
embedding是一种嵌入技术,可以直接理解为词向量
对于一个句子或一篇文章,每个位置的重要性和信息都不同;比如在标题和摘要部分的重要性显著高于其他部分;
每个位置拥有一个独特的position_embedding,好的向量可以训练得到;
这些token embedding在训练的过程中,没有考虑上下文的关系;但是在实际运用过程中,同样的单词或token在不同语境下可能有不同含义;
架构
大多数的 transduction model 都具有encoder-decoder结构
- Encoder会构建一个输出序列到连续的中间表示序列的映射
- 在某一时刻,对于给定的,Decoder 将产生输出序列
- Transformer通过逐步堆叠自注意力层,将Encoder和Decoder全连接
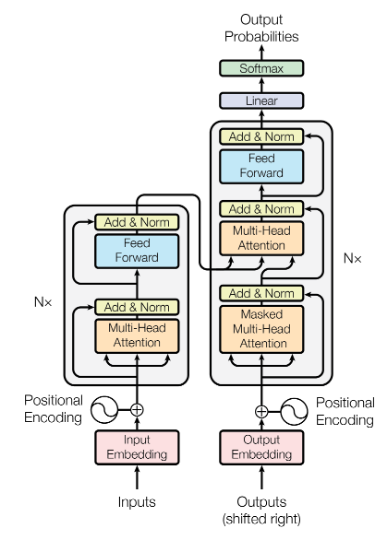
Encoder
Encoder模块堆叠个相同的layer.每个layer有两个sublayer.
- 子层1:Multi-Head Attenion;
- 子层2:feed-forward network.
在进入下一个子层前,使用残差连接(residual connection)和层正则化(layer normalization) 处理后,加上原来的输入,换言之,每个子层的输出为
所有的子层输出维度为,这样做有利于残差连接;
Decoder
Decoder模块同样堆叠个相同的layer.每个layer有3个sublayer.
- 子层0: Mask Multi-Head Attention
- 子层1:Multi-Head Attenion;
- 子层2:feed-forward network.
类似于Encoder,每个子层的输出都嵌套了残差连接和层正则化运算;
在进入多头注意力层之前,需要添加一个掩码层,这样做是因为考虑到输出的embedding 偏离了一个位置,确保位置i上的预测只依赖于该位置之前的已知输出;
Position-wise FFN
在encoder和decoder后独立添加了相同的全连接的前馈神经网络,包含了两层线性变换和一个ReLU激活层,FFN输入输出层维度为,内部层维度为;
Embedding
类似于其他序列模型,使用Embedding将输入和输出token转化为维度的向量,并使用线性变换和softmax激活函数来预测下一个token的可能性;
在两个embedding层和pre-softmax层中间使用同一个权重矩阵,在embedding层,使用一个扩大了 的权重矩阵;
Position Encoding
由于放弃了RNN,所有必须在每个token注入位置信息,Transformer在encoder和decoder堆的底部采用position encoding层,维度都是使得它们可以相加;
Transformer选择了如下的位置编码的方式,这是基于模型可以容易地学习其他位置的信息;
这个函数有个独特的性质,可以表示为的线性表示;
Attention
Attention函数可以被描述为关于query,key,value向量的函数;Attention的输出是一类对value的加权平均,权重通过query相关的key的匹配程度计算;
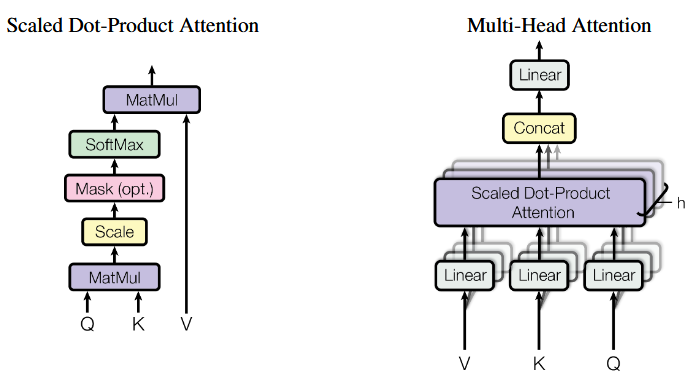
记为key向量的维度,为value的维度,下式描述了左边的缩放点积注意力机制
加性注意力机制和点性注意力机制是流行的注意力计算方式;
- 点性注意力机制:计算更快,效率更高,因为矩阵乘法已经被高度优化了,被transformer借鉴
- 加性注意力机制:复杂度相近,计算单隐藏层的前馈网络
Transformer采用多头注意力机制(Multi-Head Attention),将query,key,value划分为个线性部分,维度为,每个部分的计算是并行的;最后将计算结果拼接(concat);
其中
本文取;
Transformer在三个地方采用注意力机制
- encoder-decoder attention层中,query来自前一个decoder,而key和value来自encoder的输出,这使得decoder的每个位置都有来自先前序列的贡献,这是典型的encoder-decoder机制;
- encoder包含一个自注意力层,key, value,query都来自上一个encoder的输出,encoder每个位置都可以处理编码器上一层的所有位置;
- decoder包含的自注意力层也可以实现decoder每个位置都参与对当前位置之前的所有位置,为了防止信息向左流动,以保持auto-regressive属性,通过在缩放点注意力层,设置掩码()屏蔽来自softmax输入中非法连接;
这种自注意力机制有三个方面的优势
- 总计算复杂度降低
- 可并行化计算
- 解决在transduction tasks中长程依赖(long-range dependency)的挑战,输入输出序列的位置组合路径越短,长程依赖越容易学习
Other Tricks
- 翻译任务表现:在WMT2014英德翻译达到28.4 BLEU,英法翻译41.0 BLEU,训练耗时仅为3.5天(8 GPU),成本低于主流模型5-20倍
- 训练优化:采用Adam优化器(, )、标签平滑()和动态学习率调整;
- 位置编码对比:学习式嵌入与正弦编码效果相当,但后者支持更长序列外推
- 多头注意力有效性:8个头时性能最优,过多或过少均导致质量下降