Agent&Environment
基础概念
一个好的AI应该做到以下两点:
- think/behavior rationally
- maximize your expected utility
也就是一个理性的Agent对每一个可能的感知序列,根据已知的感知序列提供的证据和Agent具有的先验知识,理性Agent应该选择能使其性能度量最大化的行动;
那么如何设计一个合理的AI呢?PEAS描述这样的任务环境;
- 性能度量performance measuere
- 环境environment
- 执行器actuator
- 传感器sensor
一个理性的Agent不一定要做到全知,而且也很难做到,一个合理Agent基于已有感知序列进行行动,为了实现最大化期望性能,必须要做一些必要的信息收集,在位置的环境中探查;
如果一个Agent依赖于设计员的先验知识而不能子集的感知信息,则称Agent缺乏自主性,一个合理Agent应该是自主的,Agent应该学习;
但是在Agent诞生初期很难做到完全自主,当Agent经验较少时,其行为往往是随机的,那么设计者应该提供Agent一些先验知识和学习能力,当得到环境的充足经验后,理性Agent才能独立出先验知识进行有效的行动;
任务环境分类
在实践中我们经常能看到如下环境:
- 完全可观察&部分可观察
- 单Agent&多Agent
- 确定Agent&随机Agent
- 片段式&延续式
- 静态&动态
- 离散&连续
- 已知&未知
举个例子来说,自动驾驶就是要处理一个部分可观察的,多Agent,随机的,连续的,动态的,连续的和未知的环境,这每个方面都很难困难;
Simple-Reflect Agent
对于一个简单反射Agent,可以基于当前的感知选择行动,不关注感知历史,比如说每一步决策都是一个MDP,就像建立简单反射一样;
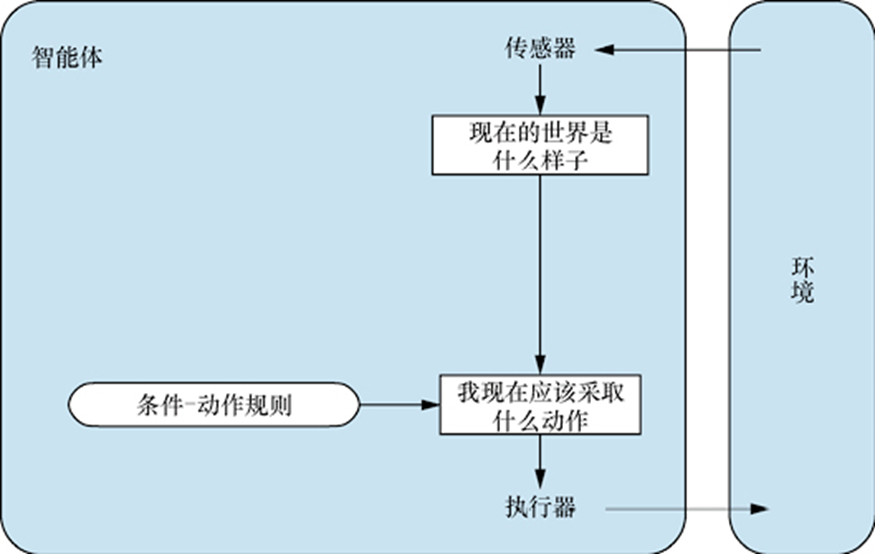
但是简单反射Agent的智能相当有限,可能会不可避免地陷入无限循环;
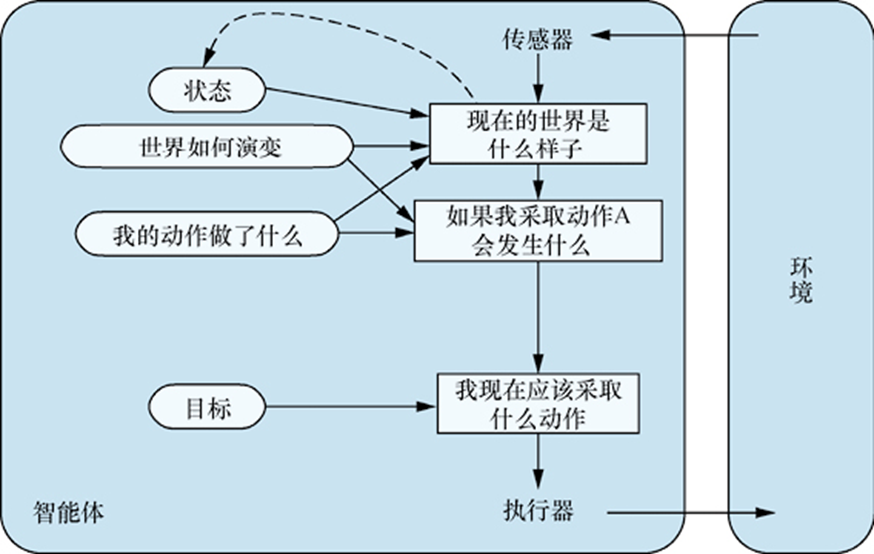
Reflect-Agent
对于一个反射性智能体,也就是基于模型的反射Agent,比如它认为状态的改变具有Markov性,为了处理部分可观测的环境,可以让Agent跟踪记录看不到的那部分世界,根据感知历史维持内部状态;
如何更新Agent的内部状态?加入两种知识,统称为世界模型:
- 世界如何独立于Agent发展
- Agent如何影响世界
对于一个当下执行一个动作将导致某种后果,作为先验知识输入到一个Reflect Agent,有如下特征:
- Choose action based on current percept (and maybe memory)
- May have memory or a model of the world’s current state
- If … now, then …
- Do not consider the future consequences of their actions
- Consider how the world IS now
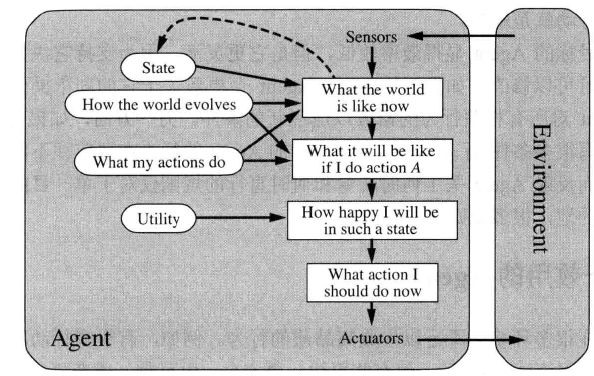
Planning-Agent
对于一个基于目标的Agent,也许Agent需要一条漫长的行动序列来找到目标途径,这时搜索和规划就是好的方法,特征如下:
- Ask “what if”
- Decisions based on (hypothesized) consequences of actions
- Must have a model of how the world evolves in response to actions
- Must formulate a goal (test)
- Consider how the world WOULD BE
一个基于模型和目标的Agent,要记录世界的状态,也要记录到达的目标集合,选择能达到最终目标的方向行动,如下图;
也有几个改进的版本:
- Optimal Planning:最小化代价去实现目标;
- Complete Planning: 找到全局最优解;
- Replanning:每次规划距离当前最近的点,采用启发式的方法;
基于效用的Agent
Agent的效用就是性能度量的内在化,基于效用的Agent试图最大化它期望的快乐,从而做出理性的决策;
- 多目标冲突时,部分目标可达到时,效用函数可以进行适当的折中;
- 无目标有把握达到时,效用函数可以对依据目标的重要性对成功进行似然加权;
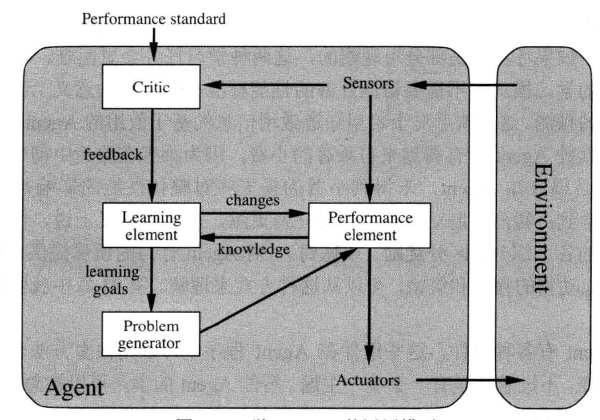
学习Agent
人工智能最需要的就是需要一个在初始未知的环境中运转并逐渐提升的Agent,一个学习Agent似乎能做到这一切,它被分为四个概念组件:
- 评判元件Critic:告诉学习元件Agent的运转情况,进行反馈;
- 学习元件Learning Element:负责Agent的改进提高,制定更好的规则;
- 问题产生器Problem generator:建议探索性的活动;
- 性能元件Performance element:负责选择外部行动,发生状态的转移和世界的改变;