基于划分的聚类算法:K-means
基于划分的聚类算法:K-means
基于划分的办法
算法初始化一个划分,之后通过迭代的办法优化这个划分方式;
如何定义优化?我们需要一个聚类目标函数作为指标:簇对象到簇中心平方误差
$$
E=\sum_{i=1}^{k} \sum_{x \in C_{i}}\left|x-\bar{x}_{i}\right|^{2}
$$
对于$K-means$算法,实现初始均值-簇分配-更新均值-收敛,如下:

一个直观的例子如图所示:
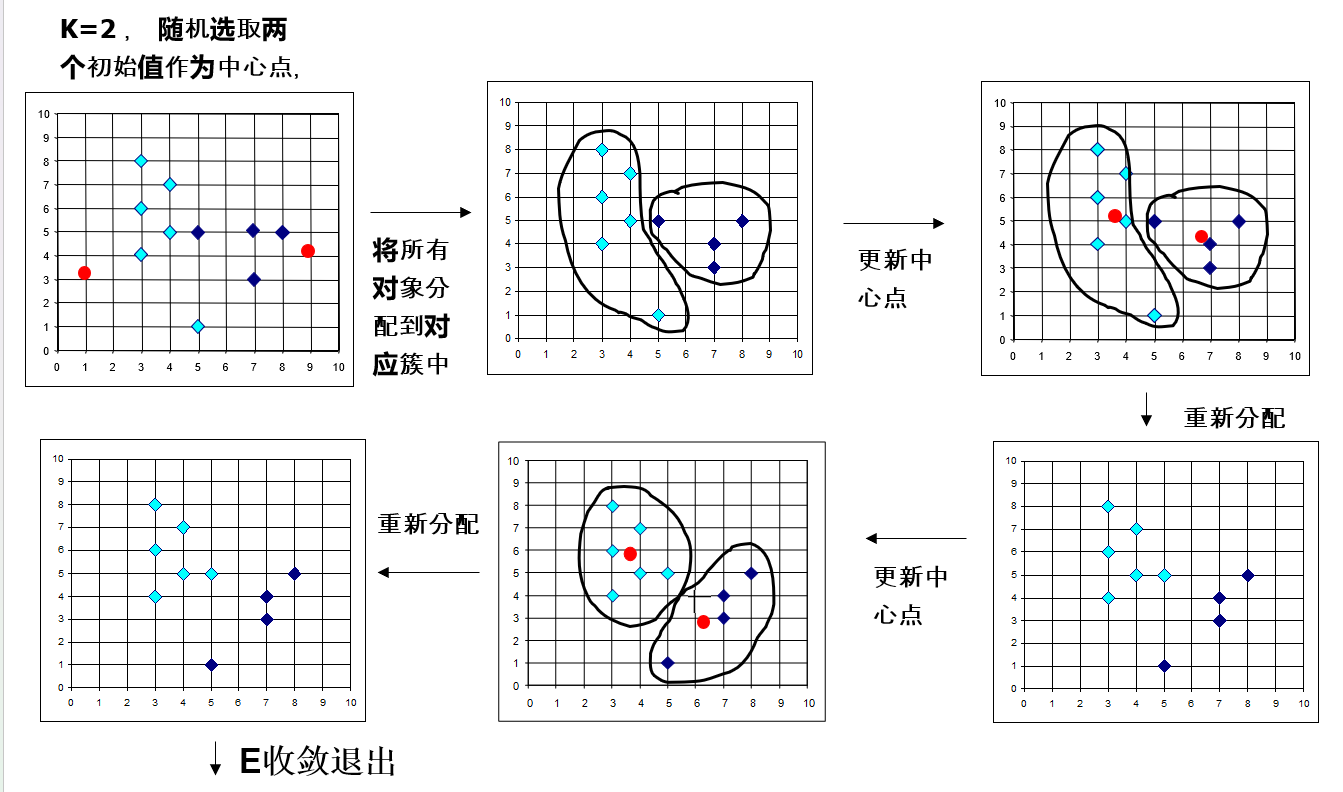
优点:
- 经典算法,简单、快速。
- 对处理大数据集,该算法是相对可伸缩和高效率的。
缺点:
- 初始值敏感;
- K需要预先设定,不是**Parameter-free **的;
- 只能发现类球状簇,不适合于发现非球形状的簇或者大小差别很大的簇;
- 离群点敏感;